Hochverfügbarkeit und Lastverteilung sind essentiell für den Aufbau von Systemen, die online bleiben und Traffic effizient verarbeiten, auch bei Ausfällen oder hoher Nachfrage. Hochverfügbarkeit gewährleistet Betriebszeit durch Eliminierung von Single Points of Failure und Verwendung von Redundanz, während Lastverteilung Traffic auf mehrere Server verteilt, um Serverüberlastung zu vermeiden.
Wichtigste Erkenntnisse:
- Hochverfügbarkeit: Hält Systeme trotz Ausfällen am Laufen. Die Betriebszeit wird in "Neunen" gemessen (z. B. 99,99% = ~52,6 Minuten Ausfallzeit/Jahr).
- Lastverteilung: Leitet Traffic über Server, um Performance zu erhalten und Engpässe zu vermeiden.
- Techniken für Hochverfügbarkeit:
- Redundanz: Mehrere Server oder Komponenten, die bereit sind, bei Ausfällen zu übernehmen.
- Health Checks: Proaktive Überwachung der Servergesundheit, um Störungen zu vermeiden.
- Failover: Automatisches Umschalten auf Backup-Systeme bei Problemen.
- Lastverteilungsalgorithmen:
- Round Robin: Durchläuft Server gleichmäßig nacheinander.
- Least Connections: Sendet Traffic zum am wenigsten ausgelasteten Server.
- IP Hash: Leitet Anfragen desselben Benutzers zum gleichen Server.
- Consistent Hashing: Begrenzt Traffic-Umverteilung beim Hinzufügen/Entfernen von Servern.
- Layer 4 vs. Layer 7 Lastverteilung:
- Layer 4: Schnell, arbeitet auf der Transportschicht (IP/Port-basiertes Routing).
- Layer 7: Intelligenter, arbeitet auf der Anwendungsschicht (Routing basierend auf URLs, Headern usw.).
Durch die Kombination dieser Strategien können Systeme effizient skaliert, Ausfallzeiten minimiert und zuverlässiger Service unter verschiedenen Bedingungen bereitgestellt werden.
Was ist Hochverfügbarkeit im System Design?
Hochverfügbarkeit definieren
Hochverfügbarkeit (HA) stellt sicher, dass Systeme betriebsbereit und zugänglich bleiben, auch wenn Teile des Systems ausfallen. Es geht darum, unterbrechungsfreien Service zu liefern, egal welche Störungen auftreten.
"Hochverfügbarkeit (HA) ist eine Eigenschaft eines Systems, das darauf abzielt, ein vereinbartes Niveau der Betriebsleistung, normalerweise Betriebszeit, für einen längeren als normalen Zeitraum zu gewährleisten." – Robert Sheldon, Technical Contributor, TechTarget [6]
Verfügbarkeit wird oft in "Neunen" ausgedrückt, die Betriebszeitprozentsätze darstellen. Zum Beispiel:
- 99,9% (drei Neunen): Etwa 8,77 Stunden Ausfallzeit pro Jahr
- 99,99% (vier Neunen): Ungefähr 52,6 Minuten Ausfallzeit pro Jahr
- 99,999% (fünf Neunen): Nur etwa 5,26 Minuten Ausfallzeit pro Jahr
Diese Zahlen sind nicht nur theoretisch – sie haben echte finanzielle Konsequenzen. 1996 schätzte ein IBM-Bericht von 1998, dass Ausfallzeiten US-amerikanische Unternehmen 4,54 Milliarden Dollar kosteten. Klar ist: Die Einsätze für Betriebszeit sind hoch.
Wie man Hochverfügbarkeit erreicht
Die Erreichung von Hochverfügbarkeit erfordert sorgfältige Planung und Strategien, um Systeme resilient zu halten. Hier sind einige wichtige Methoden:
-
Eliminierung von Single Points of Failure (SPOF): Ein einzelner ausfallender Komponente sollte nicht das gesamte System zum Absturz bringen. Zum Beispiel erreicht Stripe 99,99% Verfügbarkeit für seine Payment-API durch die Verwendung von Zone-aware Database Sharding. Jeder Datenshard hat einen primären Knoten in einer Verfügbarkeitszone und synchrone Replicas in zwei anderen. Dieses Setup ermöglicht Failover unter einer Sekunde bei niedriger Latenz – kritisch für ihre Operationen [7].
-
Redundanz: Das Duplizieren kritischer Komponenten stellt sicher, dass Backups bereit sind, bei Ausfällen zu übernehmen. Netflix demonstrierte dies während des AWS US-East-1-Ausfalls im Dezember 2021. Ihre Multi-Region Active-Active-Architektur leitete Traffic automatisch zu gesunden Regionen um. Sie verwenden auch Tools wie "Chaos Monkey", um Ausfälle zu simulieren und sicherzustellen, dass ihre Wiederherstellungsprozesse wie beabsichtigt funktionieren [7].
-
Tiefe Health Checks: Diese gehen über grundlegende Checks hinaus, um vollständige Funktionalität sicherzustellen. Zum Beispiel könnte ein Health Check nicht nur bestätigen, dass eine Datenbank läuft, sondern auch überprüfen, dass die Datenbank Abfragen ausführen kann. Dieser proaktive Ansatz ermöglicht automatisierte Failover, bevor Benutzer betroffen sind [7].
Als nächstes werden wir untersuchen, wie Lastverteilung eine entscheidende Rolle bei der Unterstützung von Hochverfügbarkeit spielt.
Wie Lastverteilung Hochverfügbarkeit unterstützt
Wie Load Balancer funktionieren
Lastverteilung spielt eine kritische Rolle bei der Gewährleistung von Hochverfügbarkeit durch effiziente Traffic-Leitung und Aufrechterhaltung der Systemverfügbarkeit. Stellen Sie sich Load Balancer als geschickte Verkehrskontrolleure vor, strategisch zwischen Benutzern und Servern positioniert, um jede Anfrage zum besten möglichen Ziel zu leiten.
"Ein Load Balancer ist grundsätzlich ein Verkehrspolizist an der Kreuzung zwischen Clients und Servern, der jede Anfrage basierend auf einer Reihe von Regeln, Richtlinien und Echtzeitbeobachtungen über die Gesundheit und Kapazität des Server-Pools zum am besten geeigneten Ziel leitet." – Matt Klein, Creator of Envoy Proxy [5]
Diese Systeme überwachen ständig die Gesundheit von Backend-Servern. Wenn ein Server nicht mehr antwortet, leitet der Load Balancer schnell Traffic zu funktionierenden Servern um und gewährleistet unterbrechungsfreien Service.
Load Balancer werden an verschiedenen Punkten innerhalb der Systemarchitektur bereitgestellt: zwischen Benutzern und Webservern, zwischen Web- und Anwendungsservern und sogar zwischen Anwendungsservern und Datenbanken [4]. Dieser geschichtete Ansatz gewährleistet einen stetigen Traffic-Fluss über das gesamte System.
Warum Lastverteilung Hochverfügbarkeit verbessert
Der herausragende Vorteil der Lastverteilung ist ihre Fähigkeit, Engpässe zu verhindern und Single Points of Failure zu eliminieren. Durch die Verteilung von Anfragen auf mehrere Server wird kein einzelner Server überfordert, was hilft, kontinuierlichen Service zu erhalten [5].
Lastverteilung unterstützt auch horizontale Skalierbarkeit, was es einfach macht, mehr Server hinzuzufügen, wenn Traffic zunimmt, ohne die Systemstabilität zu beeinträchtigen. Zum Beispiel konnte in den 2010er Jahren ein 5.000-Dollar-Server mit Open-Source HAProxy Traffic-Lasten verarbeiten, die zuvor eine 100.000-Dollar-Hardware-Lösung erforderten [5].
Diese Methode erleichtert auch Wartung und Upgrades ohne Ausfallzeiten. Sie ermöglicht nahtlose Zero-Downtime-Deployments und gibt Teams die Flexibilität, Änderungen vorzunehmen, ohne Benutzerzugriff zu unterbrechen [8].
Es ist jedoch essentiell, sicherzustellen, dass der Load Balancer selbst nicht zu einem schwachen Punkt wird. Die Verwendung redundanter Load Balancer in Active-Passive- oder Active-Active-Setups stellt sicher, dass bei Ausfall eines anderen sofort übernimmt [2].
Als nächstes werden wir uns in die Algorithmen vertiefen, die Lastverteilung so effektiv machen, als Teil Ihrer Vorbereitung auf technische Interviews und wie man den richtigen für Ihre Anforderungen wählt.
Lastverteilungsalgorithmen erklärt
Hauptlastverteilungsalgorithmen
Die Wahl des richtigen Algorithmus ist der Schlüssel zur effektiven Traffic-Verteilung. Round Robin ist eine unkomplizierte Methode, die Server sequenziell durchläuft und Anfragen nacheinander an jeden sendet. Es ist eine großartige Lösung für Setups, bei denen Server identische Hardware haben und zustandslose Anwendungen ausführen. Interessanterweise ist dies der Standard-Algorithmus für NGINX und wird in über 100.000 Deployments verwendet[9][16].
Least Connections geht einen Schritt weiter, indem es aktive Sessions überwacht und neue Anfragen zum Server mit den wenigsten aktuellen Verbindungen leitet. Dies macht es ideal für Szenarien mit langlebigen Verbindungen, wie WebSockets, Streaming-Plattformen oder Datenbanken, bei denen Sitzungsdauern erheblich variieren. HAProxy verlässt sich darauf als Standard für TCP-Lastverteilung[10][16].
Für Anwendungen, die Session-Persistenz erfordern, wie Einkaufswagen oder Chat-Systeme, stellt IP Hash sicher, dass Anfragen von der gleichen Client-IP immer zum gleichen Server geleitet werden. Dies kann jedoch zu ungleichmäßiger Traffic-Verteilung führen, wenn viele Clients eine einzelne IP teilen, wie diejenigen hinter einem NAT[12][14].
Consistent Hashing ist besonders nützlich beim Skalieren auf oder ab, da es die Anzahl der neu zugeordneten Anfragen auf etwa 1/n begrenzt, wenn ein Server hinzugefügt oder entfernt wird. Diese Funktion ist besonders wertvoll für verteilte Caches wie Redis oder Memcached, die oft virtuelle Knoten verwenden, um ausgewogene Verteilung zu gewährleisten[11][12].
Gewichtete Versionen von Algorithmen wie Round Robin und Least Connections ermöglichen die Verteilung von Traffic basierend auf Serverkapazität. Zum Beispiel verarbeitet ein Server mit einem Gewicht von 10 doppelt so viel Traffic wie einer mit einem Gewicht von 5. Least Response Time kombiniert Geschwindigkeit und Last, indem Traffic zum Server mit der schnellsten Antwortzeit und den wenigsten Verbindungen geleitet wird, während Resource-Based-Methoden Traffic dynamisch basierend auf Echtzeit-CPU- und Speichernutzung zuordnen[9][10][13].
Auswahl des richtigen Algorithmus
Ihre Wahl des Algorithmus hängt von Faktoren wie Serverfähigkeiten, Verbindungstypen und Session-Anforderungen ab.
"Eine gute Faustregel ist, einfach zu beginnen und sich weiterzuentwickeln, wie die Anforderungen es diktieren." – Maurice McMullin, Principal Product Marketing Manager, Progress Kemp[9]
Wenn Ihre Server identisch sind und schnelle, zustandslose Anfragen verarbeiten, ist Round Robin ein zuverlässiger Ausgangspunkt. Wenn Ihr Server-Pool jedoch in der Kapazität variiert, können gewichtete Algorithmen helfen, Traffic gleichmäßiger zu verteilen, ohne schwächere Maschinen zu überlasten[9][10].
Für gemischte Workloads, wie Anwendungen, die sowohl kurze API-Aufrufe als auch lange Uploads verarbeiten, ist Least Connections eine solide Wahl. Systeme, die stark auf lokales Caching angewiesen sind, profitieren andererseits von Consistent Hashing, das Cache-Hit-Raten verbessert, indem konsistentes Routing beibehalten wird[11][16].
"Die Wahl des falschen Algorithmus verschwendet Kapazität – Anfragen stauen sich auf untätigen Servern, während andere überlasten." – Sanjeev Sharma, Full Stack Engineer, E-mopro[11]
Stateful-Anwendungen, wie diejenigen, die Session-Stickiness erfordern, hängen oft von IP Hash oder Cookie-basierter Affinität ab, obwohl diese Methoden die Effizienz der Lastverteilung reduzieren können[15]. Für Flexibilität bietet HAProxy über 13 verschiedene Algorithmen, um diverse Infrastruktur-Setups zu unterstützen[13].
Abschließend sind robuste Health Checks entscheidend für die Identifizierung und Entfernung fehlgeschlagener Server aus dem Pool. Mit Round Robin für grundlegende Konnektivitätstests zu beginnen ist ein praktischer Ansatz, aber die Weiterentwicklung Ihrer Strategie basierend auf echten Performance-Daten wird die besten Ergebnisse liefern[11][15].
Der ultimative Leitfaden zu Load Balancern (System Design Fundamentals)
Aufbau eines hochverfügbaren Load Balancers
Lassen Sie uns in Strategien zum Erstellen eines resilienten, hochverfügbaren Load Balancers eintauchen, basierend auf den Konzepten von Hochverfügbarkeit und Lastverteilung.
Multi-Tier Load Balancer Design
Sich auf einen einzelnen Load Balancer zu verlassen, ist ein Risiko, das kein großflächiges System sich leisten kann. Um dies zu beheben, implementieren viele Architekturen einen mehrstufigen Ansatz. Auf der obersten Ebene leitet DNS-basiertes Global Server Load Balancing (GSLB) Traffic über geografische Regionen. Darunter verarbeiten regionale Layer 4 (L4) und Layer 7 (L7) Load Balancer Traffic-Verteilung innerhalb einzelner Rechenzentren. Unterdessen verwalten Service Meshes die Kommunikation zwischen Microservices intern.
"Die Wahl zwischen L4 und L7 ist nicht entweder-oder. Die resilientesten Architekturen schichten sie, verwenden L4 für rohe Verteilung und Fehlertoleranz am Rand und L7 für anwendungsbewusste Weiterleitung näher an den Services." - Matt Klein, Creator of Envoy Proxy [5]
Dieses geschichtete Design stellt sicher, dass keine einzelne Komponente zu einem Engpass wird. Zum Beispiel stellt AWS Elastic Load Balancing automatisch redundante Knoten über mehrere Verfügbarkeitszonen bereit, um Zuverlässigkeit zu verbessern. Um DNS-Failover effektiv zu machen, setzen Sie Ihre Time-to-Live (TTL) auf 60 Sekunden oder weniger vor Infrastrukturänderungen. Höhere TTL-Werte können dazu führen, dass Clients weiterhin auf fehlgeschlagene Server zugreifen, auch nach Failover [17].
Der nächste Schritt? Integration von Health Checks und Failover-Mechanismen zur Aufrechterhaltung dieser geschichteten Resilienz.
Health Checks und Failover
Gesundheitsüberwachung ist das Herzstück, um Ihren Load Balancer reibungslos am Laufen zu halten. Es gibt zwei Hauptmethoden:
- Aktive Checks: Der Load Balancer initiiert Sonden, wie TCP-Handshakes oder HTTP-Anfragen, und erwartet eine 200 OK-Antwort.
- Passive Checks: Er beobachtet Live-Traffic auf Warnsignale wie 5xx-Fehler oder Timeouts.
Um diesen Prozess zu optimieren, setzen Sie Schwellwerte, die einen Server nach zwei Ausfällen als unhealthy markieren und drei bis fünf erfolgreiche Checks erfordern, bevor er wieder online geht [18].
Zusätzliche Techniken wie Connection Draining und Slow Start-Mechanismen verbessern die Zuverlässigkeit weiter. Connection Draining stellt sicher, dass aktive Anfragen abgeschlossen werden, bevor ein Server entfernt wird, während Slow Start Traffic zu neu wiederhergestellten Instanzen hochfährt und plötzliche Spitzen vermeidet. Für Stateful-Anwendungen synchronisieren Sie Session-Tabellen zwischen aktiven und Standby-Load-Balancern, um Benutzerunterbrechungen während Failover zu verhindern [3].
Sobald Health Checks vorhanden sind, liegt der nächste Fokus auf der Eliminierung von Single Points of Failure.
Verhinderung von Load Balancer-Ausfällen
Redundanz ist der Schlüssel zur Vermeidung von Load Balancer-Ausfällen. Zwei häufige Setups sind Active-Passive und Active-Active Konfigurationen:
- In einem Active-Passive Setup verarbeitet ein Load Balancer Traffic, während eine Standby-Einheit ihn mit Heartbeat-Signalen überwacht. Wenn der primäre ausfällt, übernimmt der Standby die gemeinsame Virtual IP (VIP) mit VRRP (mit Tools wie keepalived).
- Ein Active-Active Setup geht weiter, mit allen Load Balancern, die gleichzeitig Traffic verarbeiten. Diese Konfiguration verlässt sich auf BGP und Equal Cost Multi-Path (ECMP) Routing, um Traffic gleichmäßig zu verteilen und Kapazität zu skalieren, wenn mehr Load Balancer hinzugefügt werden.
| Feature | Active-Passive | Active-Active |
|---|---|---|
| Traffic-Verarbeitung | Ein Load Balancer verarbeitet Traffic | Alle Load Balancer verarbeiten Traffic |
| Komplexität | Niedriger; Standard für die meisten Setups | Höher; erfordert fortgeschrittenes Networking |
| Kapazität | Begrenzt auf die Kapazität einer Einheit | Skaliert mit der Anzahl aktiver Einheiten |
| Failover-Geschwindigkeit | Nahezu sofort über VRRP/Heartbeat | Kontinuierlich; Traffic verschiebt sich automatisch |
Um die maximale Failover-Ausfallzeit zu berechnen, verwenden Sie diese Formel:
Dauer = DNS TTL + (Health Check Intervall × Unhealthy Threshold) [17].
Zum Beispiel verarbeitet ein regionaler Application Load Balancer Proxy typischerweise bis zu 600 HTTP oder 150 HTTPS neue Verbindungen pro Sekunde [17]. Regelmäßiges Fault Injection Testing stellt sicher, dass Standby-Einheiten und VIP-Übergänge wie erwartet funktionieren und Ihr System auf echte Ausfälle vorbereitet bleibt.
Layer 4 vs Layer 7 Lastverteilung
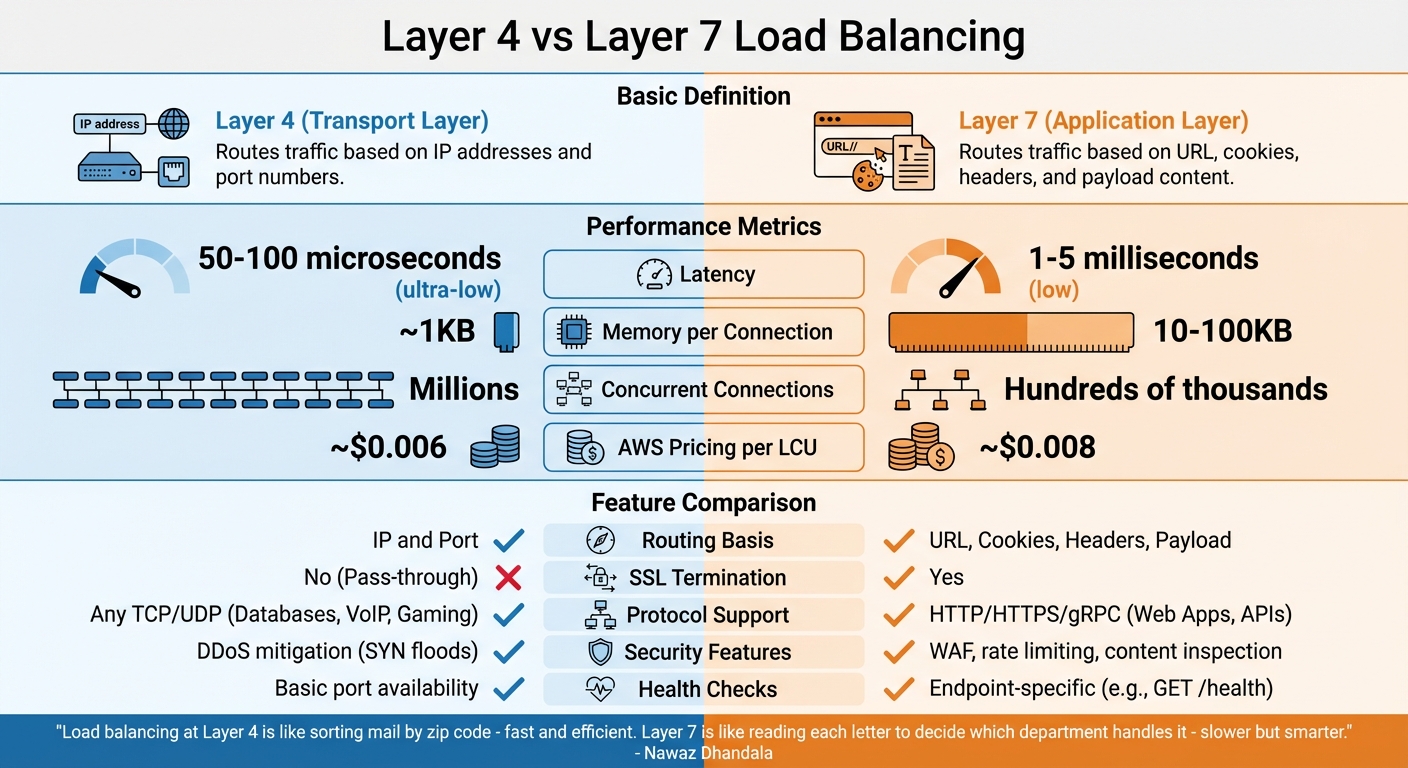
Der Unterschied zwischen Layer 4 und Layer 7 Lastverteilung liegt darin, wie sie innerhalb des Netzwerk-Stacks arbeiten. Jede bietet ein einzigartiges Gleichgewicht zwischen Geschwindigkeit und Funktionalität, je nach Ihren Anforderungen.
Layer 4 und Layer 7 erklärt
Layer 4 (Transportschicht) Load Balancer funktionieren auf TCP/UDP-Ebene und leiten Traffic basierend ausschließlich auf IP-Adressen und Portnummern. Sie inspizieren oder entschlüsseln Paketinhalte nicht, sondern leiten Traffic mit Methoden wie NAT (Network Address Translation) oder Direct Server Return (DSR) weiter. Diese Einfachheit ermöglicht schnelle Paketverarbeitung ohne Aufrechterhaltung von Anwendungszustand [19].
Layer 7 (Anwendungsschicht) Load Balancer arbeiten andererseits auf HTTP/HTTPS-Ebene. Sie beenden Client-Verbindungen, inspizieren die Anwendungsdaten und leiten dann Traffic basierend auf Faktoren wie Headern, Cookies, URLs oder Request-Payloads. Diese tiefere Inspektion ermöglicht fortgeschrittenere Entscheidungsfindung, erfordert aber das Etablieren separater Verbindungen mit Client und Backend-Server [19].
"Lastverteilung auf Layer 4 ist wie das Sortieren von Post nach Postleitzahl – schnell und effizient. Layer 7 ist wie das Lesen jedes Briefs, um zu entscheiden, welche Abteilung ihn verarbeitet – langsamer, aber intelligenter." - Nawaz Dhandala, Author, OneUptime [19]
In Bezug auf Performance bietet Layer 4 ultra-niedrige Latenz, typischerweise etwa 50–100 Mikrosekunden, und verwendet minimalen Speicher. Unterdessen führt Layer 7 leicht höhere Latenz im Bereich von 1–5 Millisekunden ein, aufgrund von Request-Pufferung und Parsing. Layer 4 kann Millionen gleichzeitiger Verbindungen verwalten, während Layer 7 generell für die Verarbeitung von Hundertausenden Anfragen pro Sekunde geeignet ist [19].
Vergleich von Layer 4 und Layer 7
Die richtige Wahl zwischen Layer 4 und Layer 7 hängt von Ihrer Workload und Ihren Zielen ab. Layer 4 ist ideal für die Maximierung des Durchsatzes, die Unterstützung von Non-HTTP-Protokollen (wie PostgreSQL oder Redis) oder die Aufrechterhaltung verschlüsselten Traffics ohne Entschlüsselung beim Load Balancer [19]. Im Gegensatz dazu ist Layer 7 besser für Web-Anwendungen geeignet, die Funktionen wie pfadbasiertes Routing (z. B. /api vs /static), SSL-Terminierung oder fortgeschrittene Sicherheitstools wie Web Application Firewalls (WAF) erfordern [19].
| Feature | Layer 4 (Transport) | Layer 7 (Anwendung) |
|---|---|---|
| Routing-Basis | IP und Port | URL, Cookies, Header, Payload |
| Latenz | Ultra-niedrig (50–100 µs) | Niedrig (1–5 ms) |
| Speicher pro Verbindung | ~1KB | 10–100KB |
| SSL-Terminierung | Nein (Pass-through) | Ja |
| Protokoll-Unterstützung | Jedes TCP/UDP (z. B. Datenbanken, VoIP, Gaming) | HTTP/HTTPS/gRPC (z. B. Web-Apps, APIs) |
| Sicherheitsfeatures | DDoS-Mitigation (z. B. SYN-Floods) | WAF, Rate Limiting, Content Inspection |
| AWS Pricing (pro LCU) | ~$0,006 | ~$0,008 |
Wenn es um Health Checks geht, verlässt sich Layer 4 auf grundlegende Port-Verfügbarkeitstests, um sicherzustellen, dass der Server erreichbar ist. Layer 7 kann jedoch detailliertere Checks durchführen, indem es auf spezifische Endpoints abzielt (z. B. GET /health), um zu überprüfen, dass die Anwendungslogik wie erwartet funktioniert [19].
Fazit
Hochverfügbarkeit und Lastverteilung sind nicht nur technische Überlegungen – sie sind das Rückgrat des modernen System Design. Diese Konzepte sind essentiell für die Aufrechterhaltung von Benutzervertrauen, die Steigerung von Einnahmen und die Gewährleistung von Betriebskontinuität. Durch die Beseitigung von Single Points of Failure und effektive Traffic-Verteilung halten sie Systeme reibungslos am Laufen, auch bei Serverausfällen oder unerwarteten Traffic-Spitzen.
Die Entwicklung von teurer Hardware zu softwaregestützten Lösungen hat Enterprise-Level-Zuverlässigkeit zugänglicher gemacht. Services wie AWS ELB und Google Cloud Load Balancing liefern nun beeindruckende Verfügbarkeitsgarantien (99,99%), was sich in nur 52 Minuten Ausfallzeit pro Jahr übersetzt [1].
Load Balancer sind mehr als nur Traffic-Verteiler – sie sind das Gehirn hinter nahtlosen Deployments, DDoS-Schutz, SSL-Terminierung und horizontaler Skalierung. Sie ermöglichen Systemen, sich an Nachfrage anzupassen, ob es eine E-Commerce-Plattform ist, die einen Holiday-Rush verarbeitet, oder ein soziales Netzwerk, das viralen Content verwaltet.
Um echte Zuverlässigkeit zu erreichen, ist Redundanz der Schlüssel. Integrieren Sie Fail-Safes auf jeder Ebene, entwerfen Sie Systeme, um zustandslos zu sein, indem Sie Tools wie Redis für Session-Management verwenden, und führen Sie Health Checks durch, die Anwendungsperformance bewerten, nicht nur Serververfügbarkeit. Willy Tarreau's Einsicht hebt die Wichtigkeit hervor, Ihren Ansatz anzupassen:
"Der ideale Lastverteilungsalgorithmus existiert nicht abstrakt – er existiert relativ zu Ihrer Workload" [5].
Ob Sie sich auf ein System Design Interview vorbereiten oder Produktionsinfrastruktur aufbauen, die Beherrschung dieser Prinzipien ist ein Game-Changer. Hochverfügbarkeit und Lastverteilung arbeiten Hand in Hand, um Systeme zu schaffen, die effizient skalieren und elegant wiederherstellen – denn selbst wenige Minuten Ausfallzeit können einen ernsthaften Einfluss auf Ihre Bilanz haben [3].
FAQs
Wie wähle ich das richtige Uptime-Ziel (99,9 vs 99,99 vs 99,999) für mein System?
Bei der Festlegung eines Uptime-Ziels sollten Sie berücksichtigen, wie kritisch Ihr System ist. Für weniger kritische Systeme ist 99,9% Uptime (etwa 8,76 Stunden Ausfallzeit pro Jahr) typischerweise ausreichend. Für mission-kritische Services – wie diejenigen im Gesundheitswesen oder in der Finanzbranche – möchten Sie jedoch ein höheres Ziel, wie 99,99% (ungefähr 52,6 Minuten Ausfallzeit pro Jahr) oder sogar 99,999% (nur 5,26 Minuten pro Jahr). Beachten Sie, dass die Erreichung höherer Uptime-Level eine viel größere Investition erfordert, daher ist es essentiell, Ihre Zuverlässigkeitsanforderungen gegen die damit verbundenen Kosten abzuwägen.
Was sollte ein "tieferer" Health Check über einen einfachen Ping hinaus beinhalten?
Bei der Durchführung eines Health Checks ist es wichtig, über einen einfachen Ping hinauszugehen. Ein gründlicher Health Check sollte alle kritischen Abhängigkeiten bewerten, wie Datenbanken und Message Queues. Dieser Ansatz bietet ein klareres Bild der Gesamtgesundheit des Systems und hilft, das Risiko von kaskadierten Ausfällen zu minimieren.
Wann sollte ich Layer 4 vs Layer 7 Lastverteilung in der Produktion verwenden?
Für Layer 4 Lastverteilung werden Routing-Entscheidungen basierend auf IP-Adressen und Ports getroffen. Dieser Ansatz ist perfekt für hochperformante Anwendungen, da er Overhead minimiert und schnelles, protokollbasiertes Routing liefert.
Andererseits konzentriert sich Layer 7 Lastverteilung auf anwendungsbewusstes Routing. Sie verwendet Inhalte wie URLs, Header oder Cookies, um Entscheidungen zu treffen, was sie ideal für komplexere Szenarien macht. Seien Sie sich jedoch bewusst, dass diese Methode höhere Latenz und mehr Ressourcennutzung im Vergleich zu Layer 4 beinhaltet.