उच्च उपलब्धता और लोड बैलेंसिंग ऐसे सिस्टम बनाने के लिए आवश्यक हैं जो ऑनलाइन रहें और विफलताओं या भारी मांग के दौरान भी ट्रैफिक को कुशलतापूर्वक संभालें। उच्च उपलब्धता एकल विफलता बिंदुओं को समाप्त करके और अतिरेक का उपयोग करके अपटाइम सुनिश्चित करता है, जबकि लोड बैलेंसिंग सर्वर ओवरलोड को रोकने के लिए ट्रैफिक वितरित करता है।
मुख्य बातें:
- उच्च उपलब्धता: विफलताओं के बावजूद सिस्टम को चलाता रहता है। अपटाइम को "नाइन्स" में मापा जाता है (उदाहरण के लिए, 99.99% = ~52.6 मिनट डाउनटाइम/वर्ष)।
- लोड बैलेंसिंग: सर्वर के पार ट्रैफिक को निर्देशित करता है ताकि प्रदर्शन बनाए रखा जा सके और बाधाओं से बचा जा सके।
- उच्च उपलब्धता के लिए तकनीकें:
- अतिरेक: यदि एक विफल हो तो लेने के लिए तैयार कई सर्वर या घटक।
- स्वास्थ्य जांच: व्यवधानों से बचने के लिए सर्वर स्वास्थ्य की सक्रिय रूप से निगरानी करें।
- फेलओवर: समस्याओं के दौरान बैकअप सिस्टम में स्वचालित स्विचिंग।
- लोड बैलेंसिंग एल्गोरिदम:
- राउंड रॉबिन: सर्वर के माध्यम से समान रूप से चक्र करता है।
- कम से कम कनेक्शन: ट्रैफिक को सबसे कम व्यस्त सर्वर को भेजता है।
- IP हैश: एक ही उपयोगकर्ता से अनुरोधों को एक ही सर्वर पर रूट करता है।
- सुसंगत हैशिंग: सर्वर जोड़े/हटाए जाने पर ट्रैफिक पुनर्वितरण को सीमित करता है।
- लेयर 4 बनाम लेयर 7 लोड बैलेंसिंग:
- लेयर 4: तेज़, परिवहन परत पर काम करता है (IP/पोर्ट-आधारित रूटिंग)।
- लेयर 7: स्मार्टर, एप्लिकेशन परत पर काम करता है (URL, हेडर आदि के आधार पर रूट करता है)।
इन रणनीतियों को जोड़कर, सिस्टम कुशलतापूर्वक स्केल कर सकते हैं, डाउनटाइम को कम कर सकते हैं, और विभिन्न परिस्थितियों में विश्वसनीय सेवा प्रदान कर सकते हैं।
सिस्टम डिज़ाइन में उच्च उपलब्धता क्या है?
उच्च उपलब्धता को परिभाषित करना
उच्च उपलब्धता (HA) सुनिश्चित करता है कि सिस्टम तब भी परिचालन और सुलभ रहें जब सिस्टम के कुछ हिस्से विफल हो जाएं। यह बिना किसी व्यवधान के निरंतर सेवा प्रदान करने के बारे में है।
"उच्च उपलब्धता (HA) एक सिस्टम की एक विशेषता है जो एक सामान्य अवधि से अधिक समय के लिए परिचालन प्रदर्शन का एक सहमत स्तर, आमतौर पर अपटाइम सुनिश्चित करने का लक्ष्य रखता है।" – रॉबर्ट शेल्डन, तकनीकी योगदानकर्ता, TechTarget [6]
उपलब्धता को अक्सर "नाइन्स" में व्यक्त किया जाता है, जो अपटाइम प्रतिशत का प्रतिनिधित्व करते हैं। उदाहरण के लिए:
- 99.9% (तीन नाइन्स): वार्षिक रूप से लगभग 8.77 घंटे का डाउनटाइम
- 99.99% (चार नाइन्स): प्रति वर्ष लगभग 52.6 मिनट का डाउनटाइम
- 99.999% (पांच नाइन्स): वार्षिक रूप से केवल लगभग 5.26 मिनट का डाउनटाइम
ये संख्याएं केवल सैद्धांतिक नहीं हैं - उनके वास्तविक वित्तीय परिणाम हैं। 1996 में, एक 1998 IBM रिपोर्ट ने अनुमान लगाया कि डाउनटाइम ने अमेरिकी व्यवसायों को $4.54 बिलियन की लागत दी। स्पष्ट रूप से, अपटाइम के लिए दांव अधिक हैं।
उच्च उपलब्धता कैसे प्राप्त करें
उच्च उपलब्धता प्राप्त करने के लिए सिस्टम को लचीला रखने के लिए सावधानीपूर्वक योजना और रणनीतियों की आवश्यकता होती है। यहाँ कुछ मुख्य तरीके दिए गए हैं:
-
एकल विफलता बिंदुओं को समाप्त करना (SPOF): एक एकल विफल घटक पूरे सिस्टम को नीचे नहीं लाना चाहिए। उदाहरण के लिए, Stripe अपने भुगतान API के लिए 99.99% उपलब्धता प्राप्त करता है जोन-जागरूक डेटाबेस शार्डिंग का उपयोग करके। प्रत्येक डेटा शार्ड के पास एक उपलब्धता क्षेत्र में एक प्राथमिक नोड और दो अन्य में सिंक्रोनस प्रतिकृतियां हैं। यह सेटअप कम विलंबता बनाए रखते हुए सबसेकंड फेलओवर की अनुमति देता है - उनके संचालन के लिए महत्वपूर्ण [7]।
-
अतिरेक: महत्वपूर्ण घटकों को डुप्लिकेट करना सुनिश्चित करता है कि यदि कुछ विफल हो तो बैकअप लेने के लिए तैयार हैं। Netflix ने दिसंबर 2021 में AWS US-East-1 आउटेज के दौरान इसका प्रदर्शन किया। उनकी मल्टी-रीजन सक्रिय-सक्रिय आर्किटेक्चर स्वचालित रूप से ट्रैफिक को स्वस्थ क्षेत्रों में पुनर्निर्देशित करता है। वे "Chaos Monkey" जैसे उपकरण भी उपयोग करते हैं विफलताओं का अनुकरण करने के लिए, यह सुनिश्चित करते हुए कि उनकी पुनर्प्राप्ति प्रक्रियाएं इच्छानुसार काम करती हैं [7]।
-
गहरी स्वास्थ्य जांच: ये बुनियादी जांच से परे जाते हैं पूर्ण कार्यक्षमता सुनिश्चित करने के लिए। उदाहरण के लिए, केवल यह पुष्टि करने के बजाय कि डेटाबेस चल रहा है, एक स्वास्थ्य जांच यह सत्यापित कर सकती है कि डेटाबेस क्वेरी निष्पादित कर सकता है। यह सक्रिय दृष्टिकोण उपयोगकर्ताओं को प्रभावित करने से पहले स्वचालित फेलओवर की अनुमति देता है [7]।
आगे, हम यह देखेंगे कि लोड बैलेंसिंग उच्च उपलब्धता का समर्थन करने में कैसे महत्वपूर्ण भूमिका निभाता है।
लोड बैलेंसिंग उच्च उपलब्धता का समर्थन कैसे करता है
लोड बैलेंसर कैसे काम करते हैं
लोड बैलेंसिंग उच्च उपलब्धता सुनिश्चित करने में महत्वपूर्ण भूमिका निभाता है ट्रैफिक को कुशलतापूर्वक निर्देशित करके और सिस्टम अपटाइम बनाए रखकर। लोड बैलेंसर को कुशल ट्रैफिक नियंत्रकों के रूप में सोचें, उपयोगकर्ताओं और सर्वर के बीच रणनीतिक रूप से रखे गए हैं प्रत्येक अनुरोध को सर्वोत्तम संभव गंतव्य पर निर्देशित करने के लिए।
"एक लोड बैलेंसर मौलिक रूप से एक ट्रैफिक पुलिस है जो क्लाइंट और सर्वर के बीच चौराहे पर खड़ा है, प्रत्येक अनुरोध को नियमों, नीतियों और सर्वर पूल के स्वास्थ्य और क्षमता के बारे में वास्तविक समय के अवलोकनों के आधार पर सबसे उपयुक्त गंतव्य पर निर्देशित करता है।" – मैट क्लेन, Envoy Proxy के निर्माता [5]
ये सिस्टम लगातार बैकएंड सर्वर के स्वास्थ्य की निगरानी करते हैं। यदि कोई सर्वर प्रतिक्रिया देना बंद कर देता है, तो लोड बैलेंसर तुरंत ट्रैफिक को कार्यात्मक सर्वर में पुनर्निर्देशित करता है, निरंतर सेवा सुनिश्चित करता है।
लोड बैलेंसर सिस्टम की आर्किटेक्चर के विभिन्न बिंदुओं पर तैनात किए जाते हैं: उपयोगकर्ताओं और वेब सर्वर के बीच, वेब और एप्लिकेशन सर्वर के बीच, और यहां तक कि एप्लिकेशन सर्वर और डेटाबेस के बीच [4]। यह स्तरीय दृष्टिकोण पूरे सिस्टम में ट्रैफिक के स्थिर प्रवाह को सुनिश्चित करता है।
लोड बैलेंसिंग उच्च उपलब्धता में सुधार क्यों करता है
लोड बैलेंसिंग का प्रमुख लाभ बाधाओं को रोकने और एकल विफलता बिंदुओं को समाप्त करने की इसकी क्षमता है। कई सर्वर के पार अनुरोधों को फैलाकर, कोई भी एकल सर्वर अभिभूत नहीं होता है, जो निरंतर सेवा बनाए रखने में मदद करता है [5]।
लोड बैलेंसिंग क्षैतिज स्केलेबिलिटी का भी समर्थन करता है, जिससे ट्रैफिक बढ़ने पर सिस्टम स्थिरता से समझौता किए बिना अधिक सर्वर जोड़ना आसान हो जाता है। उदाहरण के लिए, 2010 के दशक के दौरान, एक $5,000 सर्वर जो ओपन-सोर्स HAProxy चला रहा था, ट्रैफिक लोड को संभालता था जिसके लिए पहले एक $100,000 हार्डवेयर समाधान की आवश्यकता थी [5]।
यह विधि डाउनटाइम का कारण बने बिना रखरखाव और अपग्रेड की सुविधा भी देती है। यह निरंतर शून्य-डाउनटाइम तैनाती की अनुमति देता है, टीमों को उपयोगकर्ता पहुंच में बाधा डाले बिना परिवर्तन करने का लचीलापन देता है [8]।
हालांकि, यह सुनिश्चित करना आवश्यक है कि लोड बैलेंसर स्वयं एक कमजोर बिंदु न बन जाए। सक्रिय-निष्क्रिय या सक्रिय-सक्रिय सेटअप में अतिरेक लोड बैलेंसर का उपयोग करना सुनिश्चित करता है कि यदि एक विफल हो, तो दूसरा तुरंत लेता है [2]।
आगे, हम उन एल्गोरिदम में गोता लगाएंगे जो लोड बैलेंसिंग को आपकी तकनीकी साक्षात्कार की तैयारी के हिस्से के रूप में इतना प्रभावी बनाते हैं और आपकी आवश्यकताओं के लिए सही कैसे चुनें।
लोड बैलेंसिंग एल्गोरिदम समझाया गया
मुख्य लोड बैलेंसिंग एल्गोरिदम
सही एल्गोरिदम चुनना ट्रैफिक को प्रभावी ढंग से वितरित करने की कुंजी है। राउंड रॉबिन एक सीधी विधि है जो सर्वर के माध्यम से क्रमिक रूप से चक्र करती है, बारी-बारी से प्रत्येक को अनुरोध भेजती है। यह उन सेटअप के लिए एक बढ़िया फिट है जहां सर्वर के पास समान हार्डवेयर है और स्टेटलेस एप्लिकेशन चला रहे हैं। दिलचस्प बात यह है कि यह NGINX के लिए डिफ़ॉल्ट एल्गोरिदम है और 100,000 से अधिक तैनाती में उपयोग किया जाता है[9][16]।
कम से कम कनेक्शन सक्रिय सत्रों की निगरानी करके और नए अनुरोधों को सबसे कम वर्तमान कनेक्शन वाले सर्वर को निर्देशित करके चीजों को एक कदम आगे ले जाता है। यह लंबे समय तक चलने वाले कनेक्शन वाले परिदृश्यों के लिए आदर्श है, जैसे WebSockets, स्ट्रीमिंग प्लेटफॉर्म, या डेटाबेस जहां सत्र की अवधि काफी भिन्न होती है। HAProxy इसे TCP लोड बैलेंसिंग के लिए अपने डिफ़ॉल्ट के रूप में उपयोग करता है[10][16]।
सत्र दृढ़ता की आवश्यकता वाले एप्लिकेशन के लिए, जैसे शॉपिंग कार्ट या चैट सिस्टम, IP हैश सुनिश्चित करता है कि एक ही क्लाइंट IP से अनुरोध हमेशा एक ही सर्वर पर रूट किए जाते हैं। हालांकि, यह असमान ट्रैफिक वितरण बना सकता है यदि कई क्लाइंट एक एकल IP साझा करते हैं, जैसे NAT के पीछे वाले[12][14]।
सुसंगत हैशिंग विशेष रूप से स्केलिंग अप या डाउन करते समय उपयोगी है, क्योंकि यह पुनः मैप किए गए अनुरोधों की संख्या को लगभग 1/n तक सीमित करता है जब कोई सर्वर जोड़ा या हटाया जाता है। यह सुविधा वितरित कैश जैसे Redis या Memcached के लिए विशेष रूप से मूल्यवान है, जो अक्सर संतुलित वितरण सुनिश्चित करने के लिए आभासी नोड्स का उपयोग करते हैं[11][12]।
राउंड रॉबिन और कम से कम कनेक्शन जैसे एल्गोरिदम के भारित संस्करण सर्वर क्षमता के आधार पर ट्रैफिक वितरित करने की अनुमति देते हैं। उदाहरण के लिए, 10 का वजन वाला सर्वर 5 के वजन वाले सर्वर की तुलना में दोगुना ट्रैफिक संभालेगा। कम से कम प्रतिक्रिया समय गति और लोड को जोड़ता है सबसे तेज़ प्रतिक्रिया समय और सबसे कम कनेक्शन वाले सर्वर को ट्रैफिक निर्देशित करके, जबकि संसाधन-आधारित विधियां वास्तविक समय CPU और मेमोरी उपयोग के आधार पर गतिशील रूप से ट्रैफिक आवंटित करती हैं[9][10][13]।
सही एल्गोरिदम का चयन
आपकी एल्गोरिदम की पसंद सर्वर क्षमताओं, कनेक्शन प्रकारों और सत्र आवश्यकताओं जैसे कारकों पर निर्भर करती है।
"एक अच्छा नियम यह है कि सरल शुरू करें और आवश्यकता के अनुसार विकसित करें।" – मॉरिस मैकमुलिन, प्रिंसिपल प्रोडक्ट मार्केटिंग मैनेजर, Progress Kemp[9]
यदि आपके सर्वर समान हैं और त्वरित, स्टेटलेस अनुरोधों को संभालते हैं, तो राउंड रॉबिन एक विश्वसनीय शुरुआती बिंदु है। हालांकि, यदि आपके सर्वर पूल क्षमता में भिन्न है, तो भारित एल्गोरिदम कमजोर मशीनों को अभिभूत किए बिना ट्रैफिक को अधिक समान रूप से वितरित करने में मदद कर सकते हैं[9][10]।
मिश्रित कार्यभार के लिए, जैसे एप्लिकेशन जो संक्षिप्त API कॉल और लंबे अपलोड दोनों को संभालते हैं, कम से कम कनेक्शन एक ठोस विकल्प है। दूसरी ओर, स्थानीय कैशिंग पर बहुत अधिक निर्भर करने वाले सिस्टम सुसंगत हैशिंग से लाभान्वित होते हैं, जो सुसंगत रूटिंग बनाए रखकर कैश हिट दरों में सुधार करता है[11][16]।
"गलत एल्गोरिदम चुनना क्षमता बर्बाद करता है - अनुरोध निष्क्रिय सर्वर पर ढेर हो जाते हैं जबकि अन्य अतिप्रवाह होते हैं।" – संजीव शर्मा, फुल स्टैक इंजीनियर, E-mopro[11]
स्टेटफुल एप्लिकेशन, जैसे वे जिन्हें सत्र स्टिकीनेस की आवश्यकता है, अक्सर IP हैश या कुकी-आधारित आत्मीयता पर निर्भर करते हैं, भले ही ये विधियां लोड वितरण की दक्षता को कम कर सकती हैं[15]। लचीलेपन के लिए, HAProxy विविध बुनिधान सेटअप को समायोजित करने के लिए 13 से अधिक विभिन्न एल्गोरिदम प्रदान करता है[13]।
अंत में, विफल सर्वर की पहचान करने और पूल से हटाने के लिए मजबूत स्वास्थ्य जांच महत्वपूर्ण हैं। बुनियादी कनेक्टिविटी परीक्षण के लिए राउंड रॉबिन के साथ शुरू करना एक व्यावहारिक दृष्टिकोण है, लेकिन वास्तविक दुनिया के प्रदर्शन डेटा के आधार पर अपनी रणनीति विकसित करना सर्वोत्तम परिणाम देगा[11][15]।
लोड बैलेंसर के लिए अंतिम गाइड (सिस्टम डिज़ाइन मौलिक)
एक अत्यधिक उपलब्ध लोड बैलेंसर बनाना
आइए एक लचीला, अत्यधिक उपलब्ध लोड बैलेंसर बनाने की रणनीतियों में गोता लगाएं, उच्च उपलब्धता और लोड बैलेंसिंग की अवधारणाओं पर निर्माण करते हुए।
मल्टी-टियर लोड बैलेंसर डिज़ाइन
एक एकल लोड बैलेंसर पर निर्भर करना एक जोखिम है जो कोई भी बड़े पैमाने पर सिस्टम सहन नहीं कर सकता। इसे संबोधित करने के लिए, कई आर्किटेक्चर एक बहु-स्तरीय दृष्टिकोण लागू करते हैं। शीर्ष स्तर पर, DNS-आधारित ग्लोबल सर्वर लोड बैलेंसिंग (GSLB) भौगोलिक क्षेत्रों में ट्रैफिक निर्देशित करता है। उसके नीचे, क्षेत्रीय लेयर 4 (L4) और लेयर 7 (L7) लोड बैलेंसर व्यक्तिगत डेटा सेंटर के भीतर ट्रैफिक वितरण को संभालते हैं। इस बीच, सेवा जाल माइक्रोसर्विसेस के बीच संचार को आंतरिक रूप से प्रबंधित करते हैं।
"L4 और L7 के बीच की पसंद या तो नहीं है। सबसे लचीला आर्किटेक्चर उन्हें स्तरीय करते हैं, किनारे पर कच्चे वितरण और दोष सहिष्णुता के लिए L4 का उपयोग करते हुए, और सेवाओं के करीब एप्लिकेशन-जागरूक रूटिंग के लिए L7 का उपयोग करते हुए।" - मैट क्लेन, Envoy Proxy के निर्माता [5]
यह स्तरीय डिज़ाइन सुनिश्चित करता है कि कोई भी एकल घटक बाधा न बन जाए। उदाहरण के लिए, AWS Elastic Load Balancing विश्वसनीयता को बढ़ाने के लिए स्वचालित रूप से कई उपलब्धता क्षेत्रों में अतिरेक नोड्स तैनात करता है। DNS फेलओवर को प्रभावी बनाने के लिए, बुनिधान परिवर्तनों से पहले अपना समय-से-लाइव (TTL) 60 सेकंड या उससे कम पर सेट करें। उच्च TTL मान क्लाइंट को फेलओवर के बाद भी विफल सर्वर तक पहुंचना जारी रख सकते हैं [17]।
अगला कदम? इस स्तरीय लचीलेपन को बनाए रखने के लिए स्वास्थ्य जांच और फेलओवर तंत्र को एकीकृत करना।
स्वास्थ्य जांच और फेलओवर
स्वास्थ्य निगरानी आपके लोड बैलेंसर को सुचारू रूप से चलाने के दिल में है। दो मुख्य विधियां हैं:
- सक्रिय जांच: लोड बैलेंसर जांच शुरू करता है, जैसे TCP हैंडशेक या HTTP अनुरोध, 200 OK प्रतिक्रिया की अपेक्षा करते हुए।
- निष्क्रिय जांच: यह 5xx त्रुटियों या समय समाप्त होने जैसे चेतावनी संकेतों के लिए लाइव ट्रैफिक को देखता है।
इस प्रक्रिया को सूक्ष्म-ट्यून करने के लिए, दहलीज सेट करें जो दो विफलताओं के बाद एक सर्वर को अस्वस्थ के रूप में चिह्नित करता है और इसे फिर से ऑनलाइन लाने से पहले तीन से पांच सफल जांच की आवश्यकता होती है [18]।
कनेक्शन ड्रेनिंग और धीमी शुरुआत तंत्र जैसी अतिरिक्त तकनीकें विश्वसनीयता को और बढ़ाती हैं। कनेक्शन ड्रेनिंग सुनिश्चित करता है कि सर्वर को हटाने से पहले सक्रिय अनुरोध पूरे हो जाएं, जबकि धीमी शुरुआत नई रिकवर किए गए इंस्टेंस को ट्रैफिक को रैंप करती है, अचानक स्पाइक से बचते हुए। स्टेटफुल एप्लिकेशन के लिए, फेलओवर के दौरान उपयोगकर्ता व्यवधान को रोकने के लिए सक्रिय और स्टैंडबाय लोड बैलेंसर के बीच सत्र तालिकाओं को सिंक्रोनाइज़ करें [3]।
एक बार स्वास्थ्य जांच लागू हो जाने के बाद, अगला ध्यान एकल विफलता बिंदुओं को समाप्त करना है।
लोड बैलेंसर विफलताओं को रोकना
अतिरेक लोड बैलेंसर विफलता से बचने की कुंजी है। दो सामान्य सेटअप सक्रिय-निष्क्रिय और सक्रिय-सक्रिय कॉन्फ़िगरेशन हैं:
- एक सक्रिय-निष्क्रिय सेटअप में, एक लोड बैलेंसर ट्रैफिक को संभालता है जबकि एक स्टैंडबाय यूनिट हार्टबीट सिग्नल का उपयोग करके इसकी निगरानी करता है। यदि प्राथमिक विफल हो, तो स्टैंडबाय VRRP का उपयोग करके साझा वर्चुअल IP (VIP) लेता है (keepalived जैसे उपकरणों के साथ)।
- एक सक्रिय-सक्रिय सेटअप इसे आगे ले जाता है, सभी लोड बैलेंसर एक साथ ट्रैफिक को संसाधित करते हैं। यह कॉन्फ़िगरेशन BGP और समान लागत बहु-पथ (ECMP) रूटिंग पर निर्भर करता है ट्रैफिक को समान रूप से वितरित करने के लिए, अधिक लोड बैलेंसर जोड़े जाने पर क्षमता को स्केल करता है।
| सुविधा | सक्रिय-निष्क्रिय | सक्रिय-सक्रिय |
|---|---|---|
| ट्रैफिक हैंडलिंग | एक लोड बैलेंसर ट्रैफिक को संभालता है | सभी लोड बैलेंसर ट्रैफिक को संभालते हैं |
| जटिलता | कम; अधिकांश सेटअप के लिए मानक | अधिक; उन्नत नेटवर्किंग की आवश्यकता है |
| क्षमता | एक यूनिट की क्षमता तक सीमित | सक्रिय यूनिट की संख्या के साथ स्केल करता है |
| फेलओवर गति | VRRP/हार्टबीट के माध्यम से लगभग तत्काल | निरंतर; ट्रैफिक स्वचालित रूप से स्थानांतरित होता है |
अधिकतम फेलओवर डाउनटाइम की गणना करने के लिए, इस सूत्र का उपयोग करें:
अवधि = DNS TTL + (स्वास्थ्य जांच अंतराल × अस्वस्थ दहलीज) [17]।
उदाहरण के लिए, एक क्षेत्रीय एप्लिकेशन लोड बैलेंसर प्रॉक्सी आमतौर पर प्रति सेकंड 600 HTTP या 150 HTTPS नए कनेक्शन तक संभालता है [17]। नियमित दोष इंजेक्शन परीक्षण सुनिश्चित करता है कि स्टैंडबाय यूनिट और VIP संक्रमण अपेक्षित रूप से काम करते हैं, आपके सिस्टम को वास्तविक दुनिया की विफलताओं के लिए तैयार रखते हैं।
लेयर 4 बनाम लेयर 7 लोड बैलेंसिंग
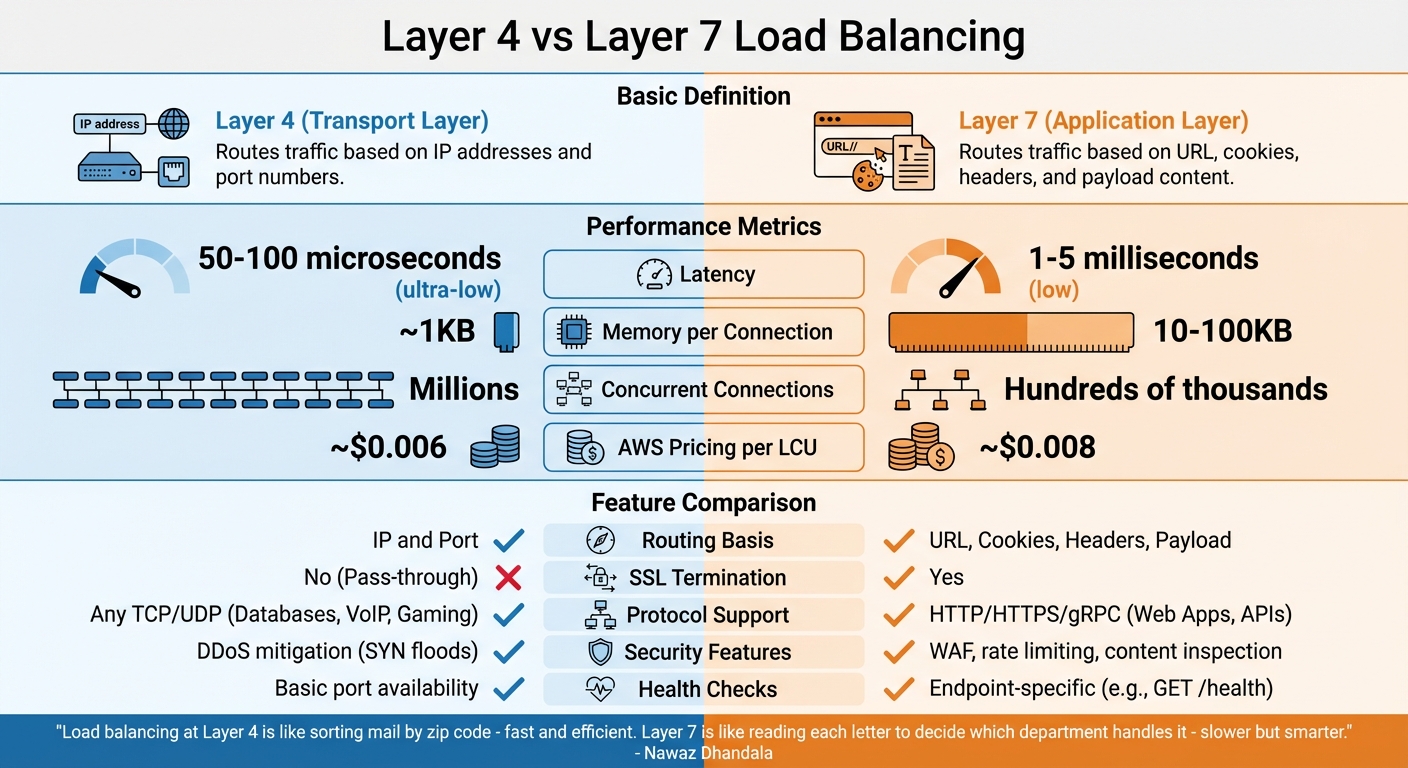
लेयर 4 और लेयर 7 लोड बैलेंसिंग के बीच का अंतर इस बात में निहित है कि वे नेटवर्क स्टैक के भीतर कैसे काम करते हैं। प्रत्येक आपकी आवश्यकताओं के आधार पर गति और कार्यक्षमता के बीच एक अद्वितीय संतुलन प्रदान करता है।
लेयर 4 और लेयर 7 समझाया गया
लेयर 4 (परिवहन परत) लोड बैलेंसर TCP/UDP स्तर पर काम करते हैं, केवल IP पते और पोर्ट नंबर के आधार पर ट्रैफिक को रूट करते हैं। वे पैकेट सामग्री का निरीक्षण या डिक्रिप्ट नहीं करते हैं, इसके बजाय NAT (नेटवर्क एड्रेस अनुवाद) या डायरेक्ट सर्वर रिटर्न (DSR) जैसी विधियों का उपयोग करके ट्रैफिक को अग्रेषित करते हैं। यह सरलता एप्लिकेशन-स्तर की स्थिति बनाए बिना त्वरित पैकेट हैंडलिंग की अनुमति देती है [19]।
लेयर 7 (एप्लिकेशन परत) लोड बैलेंसर, दूसरी ओर, HTTP/HTTPS स्तर पर काम करते हैं। वे क्लाइंट कनेक्शन को समाप्त करते हैं, एप्लिकेशन डेटा का निरीक्षण करते हैं, और फिर हेडर, कुकीज़, URL, या अनुरोध पेलोड जैसे कारकों के आधार पर ट्रैफिक को रूट करते हैं। यह गहरी जांच अधिक उन्नत निर्णय लेने को सक्षम करती है लेकिन क्लाइंट और बैकएंड सर्वर दोनों के साथ अलग कनेक्शन स्थापित करने की आवश्यकता होती है [19]।
"लेयर 4 पर लोड बैलेंसिंग मेल को ज़िप कोड द्वारा सॉर्ट करने जैसा है - तेज़ और कुशल। लेयर 7 प्रत्येक पत्र को पढ़ने जैसा है यह तय करने के लिए कि कौन सा विभाग इसे संभालता है - धीमा लेकिन स्मार्टर।" - नवाज़ ढांडला, लेखक, OneUptime [19]
प्रदर्शन के संदर्भ में, लेयर 4 अल्ट्रा-कम विलंबता का दावा करता है, आमतौर पर 50–100 माइक्रोसेकंड के आसपास, और न्यूनतम मेमोरी का उपयोग करता है। इस बीच, लेयर 7 अनुरोध बफरिंग और पार्सिंग के कारण 1–5 मिलीसेकंड की सीमा में थोड़ी अधिक विलंबता का परिचय देता है। लेयर 4 लाखों समवर्ती कनेक्शन को संभाल सकता है, जबकि लेयर 7 आमतौर पर प्रति सेकंड सैकड़ों हजार अनुरोधों को संभालने के लिए उपयुक्त है [19]।
लेयर 4 और लेयर 7 की तुलना
लेयर 4 और लेयर 7 के बीच सही विकल्प आपके कार्यभार और लक्ष्यों पर निर्भर करता है। लेयर 4 थ्रूपुट को अधिकतम करने, गैर-HTTP प्रोटोकॉल का समर्थन करने (जैसे PostgreSQL या Redis), या लोड बैलेंसर पर डिक्रिप्शन के बिना एन्क्रिप्टेड ट्रैफिक बनाए रखने के लिए आदर्श है [19]। इसके विपरीत, लेयर 7 पथ-आधारित रूटिंग (उदाहरण के लिए, /api बनाम /static), SSL समाप्ति, या वेब एप्लिकेशन फायरवॉल (WAF) जैसे उन्नत सुरक्षा उपकरणों की आवश्यकता वाले वेब एप्लिकेशन के लिए बेहतर है [19]।
| सुविधा | लेयर 4 (परिवहन) | लेयर 7 (एप्लिकेशन) |
|---|---|---|
| रूटिंग आधार | IP और पोर्ट | URL, कुकीज़, हेडर, पेलोड |
| विलंबता | अल्ट्रा-कम (50–100 µs) | कम (1–5 ms) |
| कनेक्शन प्रति मेमोरी | ~1KB | 10–100KB |
| SSL समाप्ति | नहीं (पास-थ्रू) | हाँ |
| प्रोटोकॉल समर्थन | कोई भी TCP/UDP (उदाहरण के लिए, डेटाबेस, VoIP, गेमिंग) | HTTP/HTTPS/gRPC (उदाहरण के लिए, वेब ऐप्स, API) |
| सुरक्षा सुविधाएं | DDoS शमन (उदाहरण के लिए, SYN बाढ़) | WAF, दर सीमा, सामग्री निरीक्षण |
| AWS मूल्य निर्धारण (प्रति LCU) | ~$0.006 | ~$0.008 |
स्वास्थ्य जांच के संदर्भ में, लेयर 4 बुनियादी पोर्ट उपलब्धता परीक्षण पर निर्भर करता है, यह सुनिश्चित करता है कि सर्वर पहुंचने योग्य है। लेयर 7, हालांकि, विशिष्ट एंडपॉइंट (उदाहरण के लिए, GET /health) को लक्षित करके अधिक विस्तृत जांच कर सकता है यह सत्यापित करने के लिए कि एप्लिकेशन तर्क अपेक्षित रूप से काम कर रहा है [19]।
निष्कर्ष
उच्च उपलब्धता और लोड बैलेंसिंग केवल तकनीकी विचार नहीं हैं - वे आधुनिक सिस्टम डिज़ाइन की रीढ़ हैं। ये अवधारणाएं उपयोगकर्ता विश्वास बनाए रखने, राजस्व चलाने और परिचालन निरंतरता सुनिश्चित करने के लिए आवश्यक हैं। एकल विफलता बिंदुओं को हटाकर और ट्रैफिक को प्रभावी ढंग से वितरित करके, वे सर्वर आउटेज या अप्रत्याशित ट्रैफिक स्पाइक के दौरान भी सिस्टम को सुचारू रूप से चलाते रहते हैं।
महंगे हार्डवेयर से सॉफ्टवेयर-आधारित समाधानों में विकास ने एंटरप्राइज-स्तर की विश्वसनीयता को अधिक सुलभ बना दिया है। AWS ELB और Google Cloud Load Balancing जैसी सेवाएं अब प्रभावशाली अपटाइम गारंटी (99.99%) प्रदान करती हैं, जो वार्षिक रूप से केवल 52 मिनट के डाउनटाइम में अनुवाद करती हैं [1]।
लोड बैलेंसर ट्रैफिक वितरकों से अधिक हैं - वे निरंतर तैनाती, DDoS सुरक्षा, SSL समाप्ति और क्षैतिज स्केलिंग के पीछे का दिमाग हैं। वे सिस्टम को मांग के अनुकूल होने में सक्षम करते हैं, चाहे वह एक ई-कॉमर्स प्लेटफॉर्म छुट्टी की भीड़ को संभाल रहा हो या एक सामाजिक नेटवर्क वायरल सामग्री को प्रबंधित कर रहा हो।
सच्ची विश्वसनीयता प्राप्त करने के लिए, अतिरेक महत्वपूर्ण है। हर परत पर विफलता-सुरक्षा को शामिल करें, Redis जैसे उपकरणों का उपयोग करके सत्र प्रबंधन के लिए सिस्टम को स्टेटलेस बनाने के लिए डिज़ाइन करें, और स्वास्थ्य जांच करें जो एप्लिकेशन प्रदर्शन का मूल्यांकन करें, केवल सर्वर उपलब्धता नहीं। विली तारेउ की अंतर्दृष्टि आपके दृष्टिकोण को तैयार करने के महत्व को उजागर करती है:
"आदर्श लोड बैलेंसिंग एल्गोरिदम अमूर्त रूप से मौजूद नहीं है -- यह आपके कार्यभार के सापेक्ष मौजूद है" [5]।
चाहे आप सिस्टम डिज़ाइन साक्षात्कार के लिए तैयारी कर रहे हों या उत्पादन बुनिधान बना रहे हों, इन सिद्धांतों में महारत हासिल करना एक गेम-चेंजर है। उच्च उपलब्धता और लोड बैलेंसिंग हाथ में हाथ मिलाकर ऐसे सिस्टम बनाते हैं जो कुशलतापूर्वक स्केल करते हैं और सुंदरता से पुनर्प्राप्त करते हैं - क्योंकि डाउनटाइम के कुछ मिनट भी आपके निचली पंक्ति पर गंभीर प्रभाव डाल सकते हैं [3]।
अक्सर पूछे जाने वाले प्रश्न
मैं अपने सिस्टम के लिए सही अपटाइम लक्ष्य (99.9 बनाम 99.99 बनाम 99.999) कैसे चुनूं?
अपटाइम लक्ष्य निर्धारित करते समय, विचार करें कि आपका सिस्टम कितना महत्वपूर्ण है। कम महत्वपूर्ण सिस्टम के लिए, 99.9% अपटाइम (वार्षिक रूप से लगभग 8.76 घंटे का डाउनटाइम) आमतौर पर पर्याप्त है। हालांकि, मिशन-महत्वपूर्ण सेवाओं के लिए - जैसे स्वास्थ्यसेवा या वित्त में - आप एक उच्च लक्ष्य चाहते हैं, जैसे 99.99% (वार्षिक रूप से लगभग 52.6 मिनट का डाउनटाइम) या यहां तक कि 99.999% (वार्षिक रूप से केवल 5.26 मिनट)। ध्यान रखें, उच्च अपटाइम स्तर प्राप्त करने के लिए बहुत बड़े निवेश की मांग होती है, इसलिए आपकी विश्वसनीयता आवश्यकताओं को संबंधित लागतों के विरुद्ध तौलना आवश्यक है।
एक 'गहरी' स्वास्थ्य जांच में एक साधारण पिंग से परे क्या शामिल होना चाहिए?
स्वास्थ्य जांच करते समय, एक साधारण पिंग से परे जाना महत्वपूर्ण है। एक पूर्ण स्वास्थ्य जांच को डेटाबेस और संदेश कतारों जैसी सभी महत्वपूर्ण निर्भरताओं का मूल्यांकन करना चाहिए। यह दृष्टिकोण सिस्टम के समग्र स्वास्थ्य की एक स्पष्ट तस्वीर प्रदान करता है और कैस्केडिंग विफलताओं के जोखिम को कम करने में मदद करता है।
मुझे उत्पादन में लेयर 4 बनाम लेयर 7 लोड बैलेंसिंग कब का उपयोग करना चाहिए?
लेयर 4 लोड बैलेंसिंग के लिए, रूटिंग निर्णय IP पते और पोर्ट के आधार पर किए जाते हैं। यह दृष्टिकोण उच्च-प्रदर्शन एप्लिकेशन के लिए परिपूर्ण है क्योंकि यह ओवरहेड को कम करता है और तेज़, प्रोटोकॉल-आधारित रूटिंग प्रदान करता है।
दूसरी ओर, लेयर 7 लोड बैलेंसिंग एप्लिकेशन-जागरूक रूटिंग पर ध्यान केंद्रित करता है। यह URL, हेडर, या कुकीज़ जैसी सामग्री का उपयोग करके निर्णय लेता है, जिससे यह अधिक जटिल परिदृश्यों के लिए आदर्श है। हालांकि, ध्यान रखें कि यह विधि लेयर 4 की तुलना में अधिक विलंबता और अधिक संसाधनों का उपयोग करती है।