Scalability is a key focus in system design interviews. Why? Because it shows your ability to design systems that handle increasing workloads without breaking down. This involves balancing performance, cost, and reliability - skills that are critical for senior engineers.
To succeed, you need to:
- Define clear requirements: Understand user needs, traffic patterns, and downtime limits.
- Prioritize metrics: For example, read-heavy systems need caching, while write-heavy systems benefit from partitioning.
- Choose scaling strategies wisely: Vertical scaling (upgrading hardware) is simpler but limited. Horizontal scaling (adding servers) offers more growth but adds complexity.
- Handle trade-offs: Decide between consistency and availability during failures, per the CAP theorem.
Big companies like Netflix, Twitter, and Uber provide useful examples of scaling strategies (e.g., microservices, sharding, caching). In interviews, explain your decisions, trade-offs, and how you’d ensure resilience under pressure.
Key takeaway: Scalability isn’t just about handling growth - it’s about designing systems that are efficient, reliable, and ready for change.
Scalability | System Design Interview Basics 2022
sbb-itb-20a3bee
Define Requirements and Constraints
Before you dive into designing an architecture, it’s crucial to pin down exactly what you're building. This means turning vague ideas into clear, measurable goals. As Sumit Mehrotra aptly states:
"If you can't measure it, you can't design for it. A good non-functional requirement has a number, a metric, and a clear trade-off".
Start by asking detailed, specific questions: How many Daily Active Users (DAU) will the system need to support? What’s the peak Queries Per Second (QPS)? How much downtime is acceptable? For example, if you’re building for 100 million DAU, each making 10 requests daily, you’re looking at roughly 11,500 requests per second. These numbers aren’t just stats - they’re the foundation for every decision you’ll make. Once you have them, translate these into well-defined metrics.
It’s also important to distinguish between functional requirements and non-functional requirements. Functional requirements describe what the system does - things like user actions, API endpoints, and data models. Non-functional requirements, on the other hand, focus on how well it performs, covering areas like scalability, availability, and durability. These non-functional aspects often dictate architectural strategies, such as whether to use caching, replication, or sharding.
Identify Key Metrics
The metrics you prioritize will shape your entire system design. For instance:
- A read-heavy system, like a social media feed (with typical read-to-write ratios of 100:1), will lean heavily on caching and read replicas.
- A write-heavy system, such as a logging service, requires storage optimized for writes and effective partitioning strategies.
Latency targets are another critical factor. High-performance systems often aim for a p95 latency under 200ms, while large-scale search systems might target a median query latency below 500ms. These goals influence whether certain operations can be synchronous or need to be offloaded to asynchronous queues.
Data volume estimates also play a big role. If your calculations suggest handling 180 TB of data annually, a single-node database won’t cut it. For context, a single PostgreSQL primary node typically manages 5,000 to 10,000 writes per second. If your needs surpass this, horizontal scaling becomes a must.
Availability requirements add another layer of complexity. A system with "five nines" availability (99.999%) allows for less than 6 minutes of downtime per year. Compare that to a system with 99.9% uptime, which permits about 8.76 hours of downtime annually. The engineering challenges for these two targets are worlds apart.
Understand Business Goals
Metrics alone don’t tell the whole story - you also need to consider the business objectives behind them. Your scalability and design choices should align with the system’s purpose. For example:
- A banking system needs strong consistency (ACID guarantees) and might favor SQL with synchronous replication.
- A social media feed, on the other hand, can often handle eventual consistency and benefit from NoSQL with fan-out strategies.
- Real-time chat applications typically prioritize ultra-low latency, making technologies like WebSockets and horizontal scaling ideal.
You’ll also need to decide which operations must remain functional during partial outages. For instance, reading a feed might take priority over posting a comment. Additionally, traffic patterns can vary - for example, celebrity accounts might generate disproportionately high loads. In such cases, specialized sharding strategies can help prevent bottlenecks.
Core Scalability Strategies
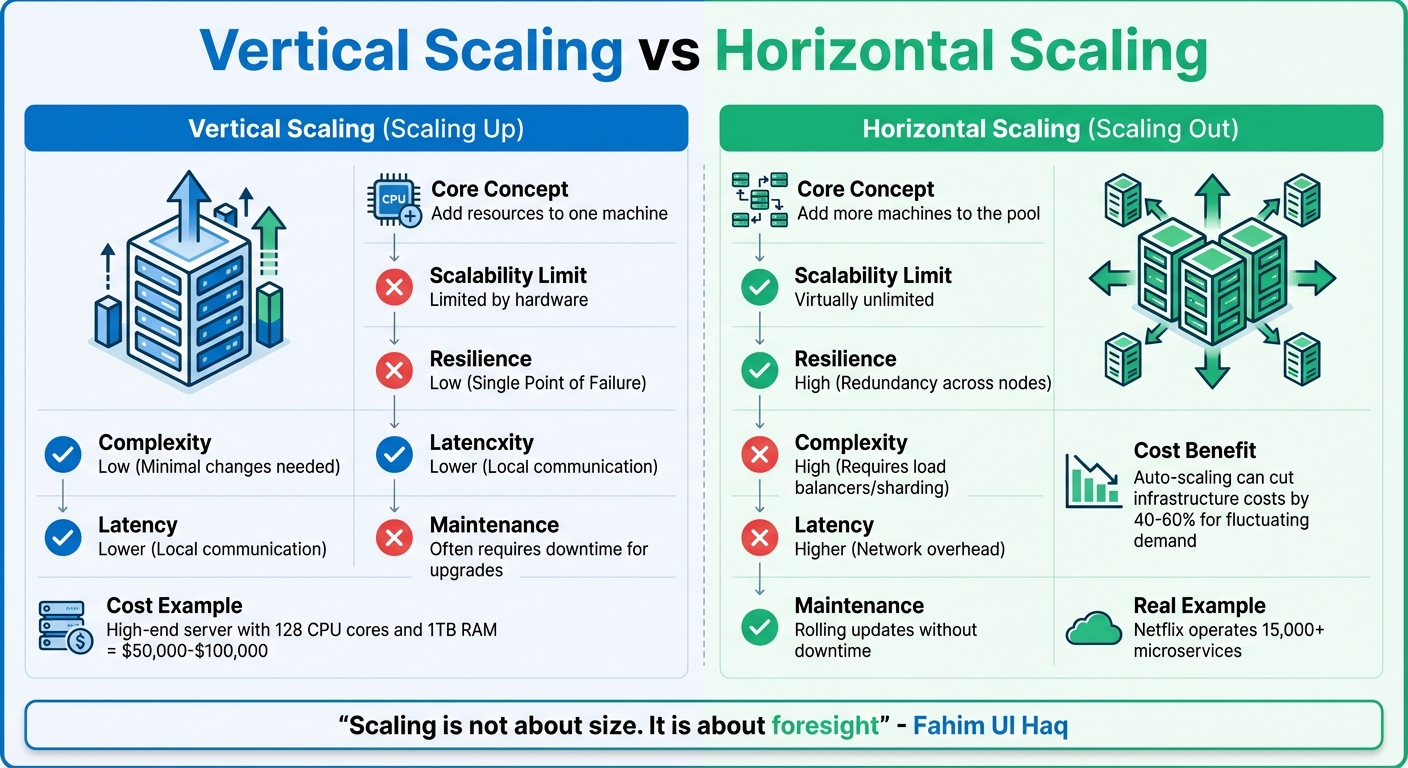
Vertical vs Horizontal Scaling: Key Differences in System Design
Once you've defined your system's requirements and metrics, it’s time to focus on scaling. In system design interviews, three key strategies often come into play: deciding between vertical and horizontal scaling, using load balancing to manage traffic, and employing caching to enhance performance. These methods often complement each other, adapting to the system's constraints and growth patterns.
Vertical Scaling vs Horizontal Scaling
Vertical scaling, or scaling up, involves upgrading a single server with more resources like CPU, RAM, or storage. Horizontal scaling, or scaling out, adds more servers to distribute the workload across multiple nodes. Each approach has its strengths and trade-offs.
| Aspect | Vertical Scaling (Scaling Up) | Horizontal Scaling (Scaling Out) |
|---|---|---|
| Core Concept | Add resources to one machine | Add more machines to the pool |
| Scalability Limit | Limited by hardware | Virtually unlimited |
| Resilience | Low (Single Point of Failure) | High (Redundancy across nodes) |
| Complexity | Low (Minimal changes needed) | High (Requires load balancers/sharding) |
| Latency | Lower (Local communication) | Higher (Network overhead) |
| Maintenance | Often requires downtime for upgrades | Rolling updates without downtime |
Vertical scaling is straightforward since it doesn’t require architectural changes. It’s a great fit for early-stage projects or internal tools, but its hardware limits can become a bottleneck. For example, a high-end server with 128 CPU cores and 1TB of RAM might cost $50,000 to $100,000.
Horizontal scaling, in contrast, allows for virtually unlimited growth and greater fault tolerance by spreading the load across multiple machines. Companies like Netflix rely on this approach, operating over 15,000 microservices to achieve global scalability. However, this method introduces complexities like load balancing, data consistency, and network latency. Despite these challenges, horizontal auto-scaling can cut infrastructure costs by 40–60% for applications with fluctuating demand, though it requires more engineering effort.
In interviews, flexibility is key. While vertical scaling is often a practical starting point, a hybrid approach - scaling databases vertically until they hit limits, then transitioning to horizontal sharding - can be highly effective. As Fahim Ul Haq aptly puts it:
"Scaling is not about size. It is about foresight".
These strategies not only address technical challenges but also demonstrate your ability to think critically during design discussions. Next, let’s explore how traffic distribution further enhances scalability.
Load Balancing and Traffic Distribution
Adding servers through horizontal scaling won’t work unless traffic is distributed effectively. Load balancers play a critical role here, acting as intermediaries that route client requests to healthy, available servers. Without them, some servers might get overwhelmed while others remain underutilized.
Load balancers use various algorithms to determine where to send requests:
- Round Robin: Distributes requests sequentially, ideal when servers have similar capacity.
- Least Connections: Routes requests to the server with the fewest active connections, useful for systems with varying processing times.
- Advanced Methods: Incorporate factors like server health, response times, or geographic proximity.
One of the biggest advantages of load balancing is its ability to support rolling updates without downtime. Servers can be taken offline for maintenance while others continue handling traffic, ensuring high availability - a must for mission-critical systems.
Caching for Performance
Efficient traffic distribution is only part of the equation. Optimizing data retrieval through caching is equally important, especially in read-heavy systems. Tools like Redis and Memcached store frequently accessed data in high-speed RAM, reducing latency and easing the load on backend databases.
Caching serves as a buffer, preventing database bottlenecks during traffic surges. Instead of querying the database for every request, cached data can be delivered in microseconds. It’s especially effective for data that doesn’t change often, such as user profiles, product catalogs, or configuration settings.
The main challenge with caching lies in maintaining data consistency. Depending on how fresh your data needs to be, you can choose from strategies like:
- Cache-Aside: Data is loaded into the cache only when requested.
- Write-Through: Data is written to the cache and database simultaneously.
- Write-Behind: Data is written to the cache first and synced to the database later.
Handle Trade-offs and Build Resilience
Scaling systems effectively means making smart trade-offs. Every design decision comes with compromises, and understanding these trade-offs is key to keeping systems reliable, even when things go sideways. In technical interviews, showcasing your ability to balance priorities and design fault-tolerant systems highlights your engineering expertise.
CAP Theorem in Practice
The CAP theorem explains that distributed systems can only guarantee two out of three properties at the same time: Consistency (ensuring all nodes have the same data), Availability (every request gets a response), and Partition Tolerance (functioning despite network failures). Since network partitions are unavoidable, the real decision boils down to whether to prioritize consistency or availability during failures.
Arslan Ahmad puts it succinctly:
"In the presence of a network partition, a distributed system must choose either Consistency or Availability".
Under normal conditions, systems often achieve both consistency and availability. However, when a partition occurs, they must choose between the two:
- CP systems prioritize consistency by rejecting requests during partitions. This approach suits use cases like financial transactions, inventory management, or distributed locks, where incorrect data could cause major issues. Google Spanner, for instance, ensures global consistency using synchronized "TrueTime" clocks while maintaining availability.
- AP systems prioritize availability by continuing to respond, even if the data becomes temporarily inconsistent. These systems resolve data conflicts later through eventual consistency. Examples include social media feeds, shopping carts, and DNS services, where brief inconsistencies are acceptable.
Modern databases like Cassandra and DynamoDB provide tunable consistency, allowing you to adjust behavior based on specific needs. For instance, you might choose CP for checkout processes but AP for product recommendations. The PACELC extension adds another dimension: during normal operations (no partitions), you trade off between Latency and Consistency. Monitoring metrics like replication lag for AP systems or write rejection rates for CP systems helps measure the impact of these choices.
Recognizing and managing these trade-offs is essential for designing systems that can handle failures and maintain reliability.
Failure Handling and Redundancy
Building resilience starts with eliminating single points of failure and ensuring systems recover quickly. Redundancy strategies play a central role here, with two main configurations:
- Active-Active: All nodes handle traffic simultaneously.
- Active-Passive: Standby nodes take over only during failures.
Data replication is another key aspect. It can be:
| Replication Mode | Synchronous | Asynchronous |
|---|---|---|
| Safety | High (waits for replica acknowledgment) | Lower (risk of recent data loss) |
| Latency | Higher (depends on network acknowledgment) | Lower (local commits are faster) |
| Use Case | Financial systems, critical data | High-throughput, social media |
For example, GitHub's October 2018 outage demonstrated the risks of replication lag. A MySQL primary failure caused metadata divergence, and the automated failover promoted a replica that lagged by 35 seconds, resulting in lost data. This highlights the importance of checking replica freshness before promotion. Shopify’s Orchestrator tool addresses such issues by comparing Global Transaction ID positions to ensure the most current replica is promoted, redirecting traffic within 30 seconds and excluding replicas with significant lag.
Geographic redundancy adds another layer of protection by deploying systems across multiple regions with global load balancing. Techniques like heartbeat signals detect unresponsive components, while leader election protocols such as Paxos or Raft promote healthy replicas automatically. Using idempotency keys prevents duplicate transactions during retries, and chaos engineering - intentionally introducing failures - tests the effectiveness of redundancy mechanisms.
To achieve "four nines" (99.99%) uptime, which allows for less than 52.56 minutes of downtime annually, systems need robust failure handling from the outset. This level of reliability requires careful planning and execution at every step.
Navigating these trade-offs not only improves scalability but also strengthens your system's ability to withstand pressure.
Learn from Real-World Examples
Looking at how major tech companies tackle scalability challenges can give you solid, real-world patterns to reference in interviews. These examples provide practical insights into strategies, reinforcing key points you can bring up during discussions.
Netflix: Microservices Architecture
Netflix made a significant shift from a single, monolithic application to a system of independent microservices. Each microservice handles a specific function, such as billing, recommendations, or video playback. This setup allows high-demand services to scale horizontally without affecting others. Even if one service fails, the rest of the platform continues to function smoothly.
Here’s a snapshot of Netflix’s scale: it processes 500 billion data events daily, consuming 1.3 petabytes of data, and can handle up to 8 million events per second during peak times. Serving 260 million subscribers, Netflix uses custom tools like Zuul for API routing, Eureka for service discovery, Hystrix to prevent cascading failures, and Ribbon for load balancing. Additionally, their private CDN, Open Connect, achieves a 98% cache hit rate, meaning only 2% of traffic reaches their origin servers.
Netflix also employs a hybrid data storage strategy: MySQL handles transactions requiring ACID compliance, such as billing, while Cassandra manages distributed data like viewing history. In interviews, discussing the operational complexity of microservices and how tools like distributed tracing can help debug issues demonstrates a deeper understanding of scalability and reliability in system design.
Twitter: Sharding and Caching
In its early years, Twitter stored all tweets in a single massive MySQL table. As traffic surged to thousands of tweets per second, this setup created bottlenecks, leading to slow queries and frequent crashes. To address this, Twitter implemented sharding using a framework called Gizzard, distributing data across multiple MySQL servers and evolving their approach to manage read-heavy workloads.
With 300 million active users generating about 6,000 tweets per second but making 600,000 timeline requests per second, Twitter faced a massive read-heavy workload. They transitioned from a "fan-in on read" model to a "fan-out on write" approach, where tweets are precomputed and stored in timeline caches (using Redis) for all followers when posted. However, for users with millions of followers, like celebrities, this fan-out approach proved too resource-intensive. Instead, Twitter dynamically pulls celebrity tweets at read-time and merges them into timelines.
To manage unique IDs across sharded databases, Twitter developed Snowflake, which generates 64-bit, time-ordered IDs without a central bottleneck. The system now handles about 1 billion tweets per day (around 12,000 transactions per second), with timeline reads spiking to 5–10 times the base rate of 70,000 requests per second. Bringing up these adaptive strategies during an interview shows your understanding of balancing scalability trade-offs.
Uber: Elastic Scaling for Demand Spikes
Uber’s infrastructure supports over 150 million database reads per second across approximately 2,200 microservices. During high-demand events, traffic can surge up to 10× normal levels. To manage this, Uber integrated caching directly into its "Docstore" query engine using CacheFront, allowing the cache layer (Redis) to scale independently of the storage layer (MySQL).
In November 2025, Uber’s Core Storage team used CacheFront for a workload requiring 6 million reads per second, reducing P75 latency by 75% and cutting infrastructure costs by 95% - from 60,000 to 3,000 CPU cores. As the Core Storage Team explained:
"When multiple teams are solving the same infrastructure problem, it belongs in a platform layer".
To handle demand spikes, Uber replaced traditional rate-limiting with Cinnamon, a load-shedding engine using PID (Proportional-Integral-Derivative) controllers. This tool prioritizes critical ride requests by temporarily pausing low-priority tasks during spikes. In February 2024, this approach reduced P99 latency by 70% (from 3.1 seconds to 1.0 seconds) and cut heap usage by 60% during peak overloads. Uber Software Engineer Dhyanam Vaidya noted:
"Rejecting early is almost always better than holding requests in memory until they expire".
For geospatial tasks, such as matching riders and drivers, Uber uses the H3 hexagonal hierarchical spatial index, which narrows down candidate sets from millions to hundreds in milliseconds. With driver apps sending GPS updates every 2 to 5 seconds, Uber processes around 1.25 million location updates per second during peak times.
These examples provide a strong foundation for explaining scalable architectures and their trade-offs in interviews.
Conclusion
To succeed in scalability interviews, focus on three core principles: clarifying requirements, choosing the right scaling strategies, and clearly explaining trade-offs. Start by defining both functional and non-functional requirements using tools like SPARCS, ensuring your solutions address actual needs instead of hypothetical problems.
Once you've nailed down the requirements, identify potential bottlenecks and decide between vertical scaling (adding resources to a single server) and horizontal scaling (adding more servers). Be transparent about your decisions - whether it’s opting for SQL over NoSQL or choosing eventual consistency over strong consistency during network partitions. As highlighted in the System Design Handbook:
"There is no perfect System Design. Almost every choice involves trade-offs."
Designing for resilience is equally important. Incorporate redundancy, failover mechanisms, and circuit breakers to prevent cascading failures. Companies like Netflix, Twitter, and Uber have successfully implemented these strategies, underscoring their real-world effectiveness.
Theoretical knowledge alone isn’t enough - practice is key. Repeatedly work through real-world scenarios until frameworks like RESHADED feel intuitive. Mock interviews and structured exercises can help uncover weaknesses you might not notice otherwise. Tools like Acedit (https://acedit.ai) provide AI-driven simulations, personalized Q&A, and real-time coaching, helping you articulate scalable architectures with confidence during interviews.
FAQs
How can I quickly estimate QPS and storage needs in an interview?
When estimating queries per second (QPS) and storage requirements, a structured, quick calculation can provide clarity. Start by defining the system's primary use case - is it more focused on reads or writes? This distinction shapes how resources are allocated.
Next, pinpoint the key metrics. For example, consider the number of requests per second or the total storage needed daily. Break these metrics into smaller, manageable units. For instance, calculate based on average request sizes or daily data growth. Multiply these figures by the expected user base to get a clearer picture.
Finally, always double-check your results. Ask yourself: Do these numbers make sense? Adjust any assumptions if the results seem unrealistic. This sanity check ensures you're working with practical estimates.
When should I choose vertical scaling vs horizontal scaling?
When deciding between vertical scaling and horizontal scaling, consider your system's priorities and limitations:
- Vertical scaling (scaling up) works best for smaller systems or when simplicity and low latency are critical. However, it comes with resource limitations and the risk of downtime during upgrades.
- Horizontal scaling (scaling out) is ideal for managing large-scale growth, ensuring high availability, or improving fault tolerance. Keep in mind, though, that it introduces additional complexity in managing distributed systems.
Ultimately, your choice should align with your system's specific requirements, scalability goals, and constraints.
How do I explain CAP trade-offs without overcomplicating my answer?
When discussing CAP trade-offs, it’s helpful to focus on how the system behaves when there's a network partition. This approach makes the concept more relatable by highlighting what users experience.
The key decision boils down to consistency versus availability:
- Consistency: In this case, the system ensures all nodes reflect the same data. If a request could compromise this consistency, the system will reject it. For users, this means they might encounter errors or delays, but the data they access will always be accurate and up-to-date.
- Availability: Here, the system prioritizes responding to requests, even if some nodes are out of sync. Users will always get a response, but there’s a chance the data might not be the latest version.
By framing the trade-off this way, you can clearly show whether the system leans toward rejecting requests to maintain data integrity or accepting them to remain responsive. This practical perspective makes it easier to grasp and demonstrates a deeper understanding of the concept.