高可用性とロードバランシングは、障害や高い需要の最中でもオンラインを保ち、トラフィックを効率的に処理するシステムを構築するために不可欠です。高可用性は冗長性を使用して単一障害点を排除することでアップタイムを確保し、ロードバランシングはサーバーの過負荷を防ぐためにトラフィックを分散させます。
重要なポイント:
- 高可用性: 障害が発生してもシステムを実行し続けます。アップタイムは「ナイン」で測定されます(例:99.99% = 年間約52.6分のダウンタイム)。
- ロードバランシング: トラフィックをサーバー全体に振り分けてパフォーマンスを維持し、ボトルネックを回避します。
- 高可用性の技術:
- 冗長性: 1つが故障した場合に引き継ぐ準備ができている複数のサーバーまたはコンポーネント。
- ヘルスチェック: サーバーの健全性を積極的に監視して中断を回避します。
- フェイルオーバー: 問題が発生した場合にバックアップシステムに自動的に切り替えます。
- ロードバランシングアルゴリズム:
- ラウンドロビン: サーバーを均等に順番に循環させます。
- 最小接続数: 最も負荷が低いサーバーにトラフィックを送信します。
- IPハッシュ: 同じユーザーからのリクエストを同じサーバーにルーティングします。
- 一貫性ハッシング: サーバーが追加/削除されたときのトラフィック再分散を制限します。
- レイヤー4対レイヤー7ロードバランシング:
- レイヤー4: 高速で、トランスポート層で動作します(IP/ポートベースのルーティング)。
- レイヤー7: より高度で、アプリケーション層で動作します(URL、ヘッダーなどに基づいてルーティング)。
これらの戦略を組み合わせることで、システムは効率的にスケーリングでき、ダウンタイムを最小化し、様々な条件下で信頼性の高いサービスを提供できます。
システム設計における高可用性とは?
高可用性の定義
高可用性(HA)は、システムの一部が故障した場合でも、システムが運用可能でアクセス可能な状態を保つことを保証します。これは、どのような中断が発生しても、中断のないサービスを提供することがすべてです。
"高可用性(HA)は、通常より長い期間、通常より高いレベルの運用パフォーマンス(通常はアップタイム)を確保することを目的とするシステムの特性です。" – Robert Sheldon、テクニカルコントリビューター、TechTarget [6]
可用性は「ナイン」で表現されることが多く、これはアップタイムのパーセンテージを表します。例えば:
- 99.9%(3つのナイン): 年間約8.77時間のダウンタイム
- 99.99%(4つのナイン): 年間約52.6分のダウンタイム
- 99.999%(5つのナイン): 年間約5.26分のダウンタイムのみ
これらの数字は単なる理論ではなく、実際の経済的影響があります。1996年に遡ると、1998年のIBMレポートは、ダウンタイムが米国企業に45.4億ドルの損失をもたらしたと推定しました。明らかに、アップタイムの利害関係は高いのです。
高可用性を実現する方法
高可用性を実現するには、システムの耐性を保つための慎重な計画と戦略が必要です。以下は主な方法です:
-
単一障害点(SPOF)の排除: 単一の故障したコンポーネントがシステム全体をダウンさせるべきではありません。例えば、Stripeは、ゾーン対応データベースシャーディングを使用して、支払いAPIの99.99%の可用性を実現しています。各データシャードは1つの可用性ゾーンにプライマリノードを持ち、他の2つに同期レプリカを持っています。このセットアップにより、低レイテンシーを維持しながら1秒未満のフェイルオーバーが可能になります。これは彼らの運用にとって重要です [7]。
-
冗長性: 重要なコンポーネントを複製することで、何か故障した場合にバックアップが引き継ぐ準備ができていることを保証します。Netflixは2021年12月のAWS US-East-1の停止中にこれを実証しました。彼らのマルチリージョンアクティブ-アクティブアーキテクチャは、トラフィックを健全なリージョンに自動的にリダイレクトしました。彼らはまた、「Chaos Monkey」などのツールを使用して障害をシミュレートし、復旧プロセスが意図したとおりに機能することを確認しています [7]。
-
深いヘルスチェック: これらは基本的なチェックを超えて、完全な機能を確保します。例えば、データベースが実行されていることを確認するだけでなく、ヘルスチェックはデータベースがクエリを実行できることを確認する場合があります。このプロアクティブなアプローチにより、ユーザーが影響を受ける前に自動フェイルオーバーが可能になります [7]。
次に、ロードバランシングが高可用性をサポートする上でどのような重要な役割を果たすかを探ります。
ロードバランシングが高可用性をサポートする方法
ロードバランサーの仕組み
ロードバランシングは、トラフィックを効率的に振り分け、システムのアップタイムを維持することで、高可用性を確保する上で重要な役割を果たします。ロードバランサーを、ユーザーとサーバーの間に戦略的に配置された熟練したトラフィックコントローラーと考えてください。各リクエストを最適な宛先に導きます。
"ロードバランサーは基本的に、クライアントとサーバーの間の交差点に立つトラフィック警察であり、一連のルール、ポリシー、およびサーバープールの健全性と容量に関するリアルタイム観察に基づいて、各リクエストを最も適切な宛先に振り分けます。" – Matt Klein、Envoy Proxyの作成者 [5]
これらのシステムは、バックエンドサーバーの健全性を継続的に監視します。サーバーが応答を停止した場合、ロードバランサーはトラフィックを機能しているサーバーに迅速にリダイレクトし、中断のないサービスを確保します。
ロードバランサーは、システムアーキテクチャ内の様々なポイントに配置されます: ユーザーとウェブサーバーの間、ウェブサーバーとアプリケーションサーバーの間、さらにはアプリケーションサーバーとデータベースの間 [4]。この階層化されたアプローチにより、システム全体を通じてトラフィックが安定して流れることが保証されます。
ロードバランシングが高可用性を改善する理由
ロードバランシングの際立った利点は、ボトルネックを防ぎ、単一障害点を排除する能力です。複数のサーバーにリクエストを分散させることで、単一のサーバーが過負荷になることはなく、継続的なサービスを維持するのに役立ちます [5]。
ロードバランシングはまた、水平スケーラビリティをサポートし、トラフィックが増加するにつれてシステムの安定性を損なうことなく、より多くのサーバーを簡単に追加できます。例えば、2010年代には、オープンソースHAProxyを実行している5,000ドルのサーバーが、以前は100,000ドルのハードウェアソリューションが必要だったトラフィック負荷を処理していました [5]。
この方法はまた、ダウンタイムを引き起こさずにメンテナンスとアップグレードを容易にします。ユーザーアクセスを中断することなく変更を加える柔軟性を与える、シームレスなゼロダウンタイムデプロイメントを可能にします [8]。
ただし、ロードバランサー自体が弱点にならないようにすることが重要です。アクティブ-パッシブまたはアクティブ-アクティブセットアップで冗長ロードバランサーを使用することで、1つが故障した場合、別のものがすぐに引き継ぐことを保証します [2]。
次に、技術面接の準備の一部として、ロードバランシングを非常に効果的にするアルゴリズムと、ニーズに合ったものを選択する方法について詳しく説明します。
ロードバランシングアルゴリズムの説明
主なロードバランシングアルゴリズム
正しいアルゴリズムを選択することは、トラフィックを効果的に分散させるための鍵です。ラウンドロビンは、サーバーを順番に循環させ、各サーバーに順番にリクエストを送信する単純な方法です。サーバーが同じハードウェアを持ち、ステートレスアプリケーションを実行しているセットアップに最適です。興味深いことに、これはNGINXのデフォルトアルゴリズムであり、100,000以上のデプロイメントで使用されています[9][16]。
最小接続数はさらに一歩進んで、アクティブセッションを監視し、新しいリクエストを現在の接続数が最も少ないサーバーに振り分けます。これにより、WebSocket、ストリーミングプラットフォーム、またはセッション期間が大きく異なるデータベースなど、長時間の接続を伴うシナリオに最適です。HAProxyはTCPロードバランシングのデフォルトとしてこれに依存しています[10][16]。
ショッピングカートやチャットシステムなど、セッション永続性が必要なアプリケーションの場合、IPハッシュは同じクライアントIPからのリクエストが常に同じサーバーにルーティングされることを保証します。ただし、NATの背後にある多くのクライアントなど、多くのクライアントが単一のIPを共有する場合、これはトラフィック分散が不均等になる可能性があります[12][14]。
一貫性ハッシングは、スケールアップまたはスケールダウン時に特に有用です。サーバーが追加または削除されたときに、リマップされたリクエストの数を約1/nに制限するためです。この機能は、仮想ノードを使用して均衡の取れた分散を確保することが多い、RedisやMemcachedなどの分散キャッシュに特に価値があります[11][12]。
ラウンドロビンや最小接続数などのアルゴリズムの加重バージョンにより、サーバー容量に基づいてトラフィックを分散させることができます。例えば、重み付けが10のサーバーは、重み付けが5のサーバーの2倍のトラフィックを処理します。最小応答時間は速度と負荷を組み合わせ、最速の応答時間と最も少ない接続を持つサーバーにトラフィックを振り分けます。一方、リソースベースの方法は、リアルタイムのCPUとメモリ使用率に基づいてトラフィックを動的に割り当てます[9][10][13]。
正しいアルゴリズムの選択
アルゴリズムの選択は、サーバー機能、接続タイプ、セッション要件などの要因に依存します。
"経験則として、シンプルに始めて、必要に応じて進化させることです。" – Maurice McMullin、プリンシパルプロダクトマーケティングマネージャー、Progress Kemp[9]
サーバーが同じで、迅速でステートレスなリクエストを処理する場合、ラウンドロビンは信頼できる出発点です。ただし、サーバープールの容量が異なる場合、加重アルゴリズムは、より弱いマシンに過負荷をかけることなく、トラフィックをより均等に分散させるのに役立ちます[9][10]。
混合ワークロード(短いAPI呼び出しと長いアップロードの両方を処理するアプリケーションなど)の場合、最小接続数は堅実な選択肢です。一方、ローカルキャッシングに大きく依存するシステムは、一貫したルーティングを維持することでキャッシュヒット率を向上させる一貫性ハッシングから恩恵を受けます[11][16]。
"間違ったアルゴリズムを選択すると、容量が無駄になります。リクエストはアイドルサーバーに積み重なり、他のサーバーはオーバーフローします。" – Sanjeev Sharma、フルスタックエンジニア、E-mopro[11]
セッションスティッキーが必要なアプリケーションなど、ステートフルアプリケーションは、これらの方法が負荷分散の効率を低下させる可能性があるにもかかわらず、IPハッシュまたはクッキーベースのアフィニティに依存することが多いです[15]。柔軟性のために、HAProxyは多様なインフラストラクチャセットアップに対応するために13以上の異なるアルゴリズムを提供しています[13]。
最後に、堅牢なヘルスチェックは、故障したサーバーをプールから特定して削除するために重要です。基本的な接続テストのためにラウンドロビンで始めることは実用的なアプローチですが、実際のパフォーマンスデータに基づいて戦略を進化させることで、最良の結果が得られます[11][15]。
ロードバランサーの究極ガイド(システム設計の基礎)
高可用性ロードバランサーの構築
高可用性とロードバランシングの概念に基づいて、回復力のある高可用性ロードバランサーを作成するための戦略を詳しく説明します。
マルチティアロードバランサー設計
単一のロードバランサーに依存することは、大規模なシステムが負担できないリスクです。これに対処するために、多くのアーキテクチャはマルチティアアプローチを実装しています。最上位では、**DNSベースのグローバルサーバーロードバランシング(GSLB)**は地理的リージョン全体のトラフィックを振り分けます。その下に、地域のレイヤー4(L4)およびレイヤー7(L7)ロードバランサーが個々のデータセンター内のトラフィック分散を処理します。一方、サービスメッシュはマイクロサービス間の通信を内部的に管理します。
"L4とL7の選択は、どちらか一方ではありません。最も回復力のあるアーキテクチャはそれらを階層化し、エッジで生のトラフィック分散とフォールトトレランスのためにL4を使用し、サービスに近いアプリケーション対応ルーティングのためにL7を使用します。" - Matt Klein、Envoy Proxyの作成者 [5]
この階層化された設計により、単一のコンポーネントがボトルネックになることはありません。例えば、AWS Elastic Load Balancingは、信頼性を強化するために、複数の可用性ゾーン全体に冗長ノードを自動的にデプロイします。DNSフェイルオーバーを効果的にするには、インフラストラクチャの変更前にTime-to-Live(TTL)を60秒以下に設定してください。より高いTTL値は、クライアントがフェイルオーバー後も故障したサーバーへのアクセスを続ける可能性があります [17]。
次のステップは、この階層化された耐性を維持するためにヘルスチェックとフェイルオーバーメカニズムを統合することです。
ヘルスチェックとフェイルオーバー
ヘルス監視は、ロードバランサーをスムーズに実行し続けるための中心です。主に2つの方法があります:
- アクティブチェック: ロードバランサーはTCPハンドシェイクやHTTPリクエストなどのプローブを開始し、200 OKレスポンスを期待します。
- パッシブチェック: 5xxエラーやタイムアウトなどの警告兆候がないか、ライブトラフィックを観察します。
このプロセスを微調整するには、2回の失敗後にサーバーを不健全としてマークし、オンラインに戻す前に3~5回の成功したチェックが必要なしきい値を設定します [18]。
接続ドレーニングとスロースタートメカニズムなどの追加技術は、信頼性をさらに向上させます。接続ドレーニングは、サーバーを削除する前にアクティブなリクエストが完了することを保証し、スロースタートは新しく復旧したインスタンスへのトラフィックを段階的に増加させ、突然のスパイクを回避します。ステートフルアプリケーションの場合、フェイルオーバー中のユーザーの中断を防ぐために、アクティブなロードバランサーとスタンバイロードバランサー間でセッションテーブルを同期します [3]。
ヘルスチェックが実施されたら、次の焦点は単一障害点を排除することです。
ロードバランサー障害の防止
冗長性は、ロードバランサー障害を回避するための鍵です。2つの一般的なセットアップはアクティブ-パッシブとアクティブ-アクティブ構成です:
- アクティブ-パッシブセットアップでは、1つのロードバランサーがトラフィックを処理し、スタンバイユニットはハートビート信号を使用してそれを監視します。プライマリが故障した場合、スタンバイはVRRP(keepalivedなどのツール付き)を使用して共有仮想IP(VIP)を引き継ぎます。
- アクティブ-アクティブセットアップはさらに進んで、すべてのロードバランサーが同時にトラフィックを処理します。この構成はBGPと等コストマルチパス(ECMP)ルーティングに依存してトラフィックを均等に分散し、より多くのロードバランサーが追加されるにつれて容量をスケーリングします。
| 機能 | アクティブ-パッシブ | アクティブ-アクティブ |
|---|---|---|
| トラフィック処理 | 1つのロードバランサーがトラフィックを処理 | すべてのロードバランサーがトラフィックを処理 |
| 複雑さ | 低い; ほとんどのセットアップの標準 | 高い; 高度なネットワークが必要 |
| 容量 | 1つのユニットの容量に制限 | アクティブユニット数でスケーリング |
| フェイルオーバー速度 | VRRP/ハートビート経由でほぼ瞬時 | 継続的; トラフィックは自動的にシフト |
最大フェイルオーバーダウンタイムを計算するには、この式を使用します:
期間 = DNS TTL +(ヘルスチェック間隔 × 不健全しきい値) [17]。
例えば、地域のアプリケーションロードバランサープロキシは通常、1秒あたり最大600のHTTPまたは150のHTTPSの新しい接続を処理します [17]。定期的なフォルトインジェクションテストにより、スタンバイユニットとVIP遷移が期待どおりに機能することを確認し、システムが実際の障害に対して準備ができていることを保ちます。
レイヤー4対レイヤー7ロードバランシング
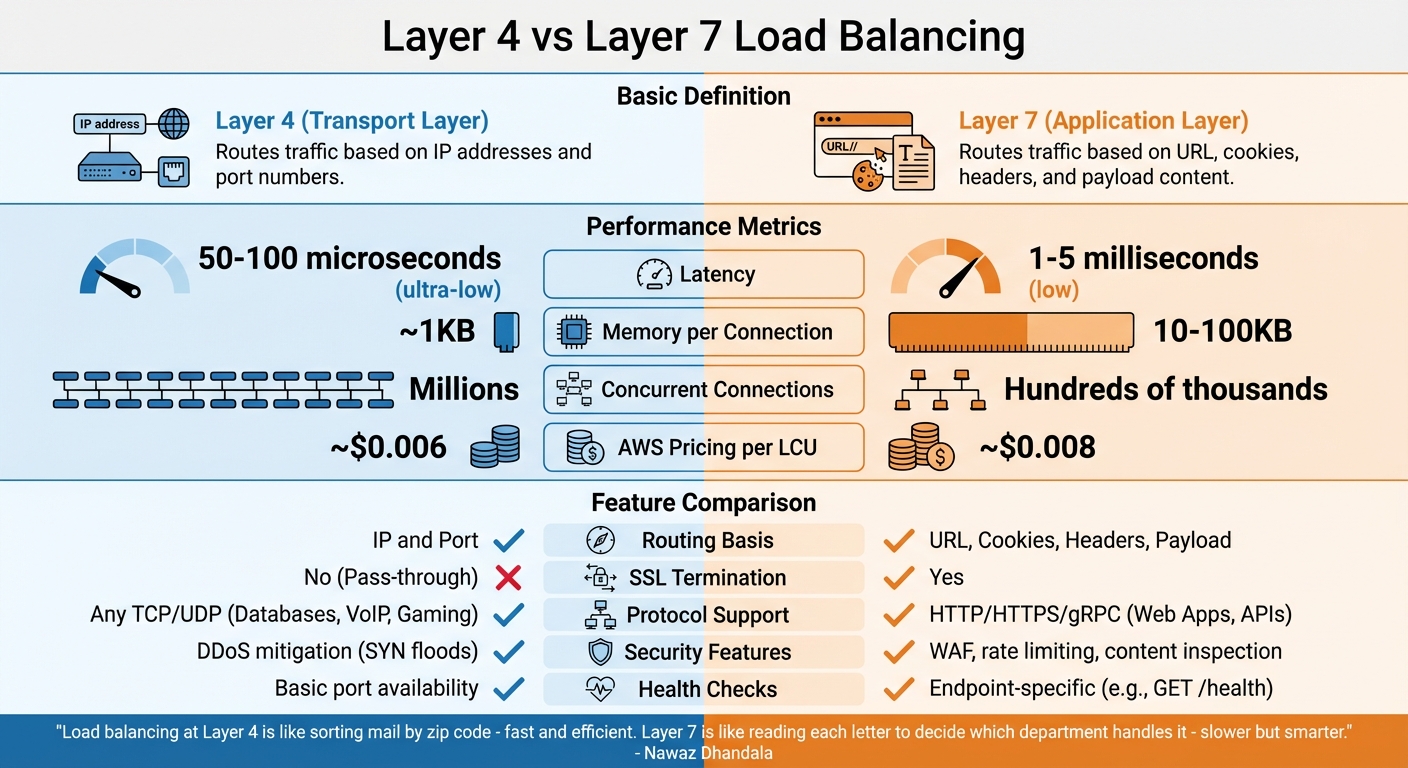
レイヤー4とレイヤー7ロードバランシングの区別は、ネットワークスタック内でどのように動作するかにあります。それぞれは、ニーズに応じて、速度と機能性のユニークなバランスを提供します。
レイヤー4とレイヤー7の説明
**レイヤー4(トランスポート層)**ロードバランサーはTCP/UDPレベルで機能し、IPアドレスとポート番号のみに基づいてトラフィックをルーティングします。パケットコンテンツを検査または復号化せず、代わりにNAT(ネットワークアドレス変換)またはダイレクトサーバーリターン(DSR)などの方法を使用してトラフィックを転送します。この単純さにより、アプリケーションレベルの状態を維持することなく、迅速なパケット処理が可能になります [19]。
一方、**レイヤー7(アプリケーション層)**ロードバランサーはHTTP/HTTPSレベルで動作します。クライアント接続を終了し、アプリケーションデータを検査し、ヘッダー、クッキー、URL、またはリクエストペイロードなどの要因に基づいてトラフィックをルーティングします。この深い検査により、より高度な意思決定が可能になりますが、クライアントとバックエンドサーバーの両方との個別の接続を確立する必要があります [19]。
"レイヤー4でのロードバランシングは郵便番号で郵便を仕分けするようなもので、高速で効率的です。レイヤー7は各手紙を読んでどの部門がそれを処理するかを決定するようなもので、遅いですがより高度です。" - Nawaz Dhandala、著者、OneUptime [19]
パフォーマンスの観点から、レイヤー4は超低レイテンシー(通常50~100マイクロ秒)を誇り、最小限のメモリを使用します。一方、レイヤー7は、リクエストバッファリングと解析のため、1~5ミリ秒の範囲でわずかに高いレイテンシーを導入します。レイヤー4は数百万の同時接続を管理できますが、レイヤー7は一般的に1秒あたり数十万のリクエストを処理するのに適しています [19]。
レイヤー4とレイヤー7の比較
レイヤー4とレイヤー7の間の正しい選択は、ワークロードと目標に依存します。レイヤー4は、スループットを最大化し、PostgreSQLやRedisなどの非HTTPプロトコルをサポートし、ロードバランサーでの復号化なしに暗号化されたトラフィックを維持するのに理想的です [19]。対照的に、レイヤー7は、パスベースのルーティング(例:/api対/static)、SSLターミネーション、またはWebアプリケーションファイアウォール(WAF)などの高度なセキュリティツールが必要なウェブアプリケーションに適しています [19]。
| 機能 | レイヤー4(トランスポート) | レイヤー7(アプリケーション) |
|---|---|---|
| ルーティング基準 | IPとポート | URL、クッキー、ヘッダー、ペイロード |
| レイテンシー | 超低(50~100 µs) | 低(1~5 ms) |
| 接続あたりのメモリ | 約1KB | 10~100KB |
| SSLターミネーション | いいえ(パススルー) | はい |
| プロトコルサポート | 任意のTCP/UDP(例:データベース、VoIP、ゲーミング) | HTTP/HTTPS/gRPC(例:ウェブアプリ、API) |
| セキュリティ機能 | DDoS軽減(例:SYNフラッド) | WAF、レート制限、コンテンツ検査 |
| AWSの価格(LCUあたり) | 約$0.006 | 約$0.008 |
ヘルスチェックに関しては、レイヤー4は基本的なポート可用性テストに依存し、サーバーに到達可能であることを確認します。一方、レイヤー7は、特定のエンドポイント(例:GET /health)をターゲットにすることで、より詳細なチェックを実行して、アプリケーションロジックが期待どおりに機能していることを確認できます [19]。
結論
高可用性とロードバランシングは単なる技術的な考慮事項ではなく、現代的なシステム設計の基盤です。これらの概念は、ユーザーの信頼を維持し、収益を促進し、運用の継続性を確保するために不可欠です。単一障害点を削除し、トラフィックを効果的に分散させることで、サーバーの停止や予期しないトラフィックスパイク中でもシステムをスムーズに実行し続けます。
高価なハードウェアからソフトウェアベースのソリューションへの進化により、エンタープライズレベルの信頼性がより利用しやすくなりました。AWS ELBやGoogle Cloud Load Balancingなどのサービスは、年間わずか52分のダウンタイムに相当する99.99%のアップタイム保証を提供しています [1]。
ロードバランサーはトラフィック分散器以上の役割を果たします。シームレスなデプロイメント、DDoS保護、SSLターミネーション、および水平スケーリングの背後にある脳です。需要に適応するシステムを有効にします。ホリデーラッシュを処理するeコマースプラットフォームであろうと、ウイルスコンテンツを管理するソーシャルネットワークであろうと。
真の信頼性を実現するには、冗長性が鍵です。すべてのレイヤーにフェイルセーフを組み込み、Redisなどのツールを使用してセッション管理を行うことでシステムをステートレスになるように設計し、アプリケーションパフォーマンスだけでなくサーバー可用性も評価するヘルスチェックを実施します。Willy Tarreau の洞察は、アプローチをカスタマイズすることの重要性を強調しています:
"理想的なロードバランシングアルゴリズムは抽象的には存在しません。それはあなたのワークロードに相対的に存在します" [5]。
システム設計面接の準備をしているか、本番インフラストラクチャを構築しているかにかかわらず、これらの原則をマスターすることはゲームチェンジャーです。高可用性とロードバランシングは手を携えて機能し、効率的にスケーリングし、優雅に復旧するシステムを作成します。数分のダウンタイムでも、あなたの収益に深刻な影響を与える可能性があるため [3]。
よくある質問
アップタイムターゲット(99.9対99.99対99.999)をどのように選択しますか?
アップタイムターゲットを設定する場合、システムがどの程度重要かを考慮してください。あまり重要でないシステムの場合、99.9%のアップタイム(年間約8.76時間のダウンタイム)は通常十分です。ただし、医療や金融などのミッションクリティカルなサービスの場合、99.99%(年間約52.6分のダウンタイム)またはさらに99.999%(年間約5.26分のダウンタイムのみ)などのより高いターゲットが必要になります。より高いアップタイム レベルを達成するには、はるかに大きな投資が必要であることに注意してください。そのため、信頼性のニーズと関連するコストのバランスを取ることが重要です。
シンプルなpingを超えた「深い」ヘルスチェックには何を含めるべきですか?
ヘルスチェックを実行する場合、シンプルなpingを超えることが重要です。徹底的なヘルスチェックは、データベースやメッセージキューなど、すべての重要な依存関係を評価する必要があります。このアプローチは、システムの全体的な健全性をより明確に把握でき、カスケード障害のリスクを最小化するのに役立ちます。
本番環境でレイヤー4対レイヤー7ロードバランシングをいつ使用すべきですか?
レイヤー4ロードバランシングの場合、ルーティング決定はIPアドレスとポートに基づいて行われます。このアプローチは、オーバーヘッドを最小化し、高速でプロトコルベースのルーティングを提供するため、高パフォーマンスアプリケーションに最適です。
一方、レイヤー7ロードバランシングはアプリケーション対応ルーティングに焦点を当てています。URL、ヘッダー、またはクッキーなどのコンテンツを使用して決定を行い、より複雑なシナリオに最適です。ただし、この方法はレイヤー4と比較してレイテンシーが高く、より多くのリソースを使用することに注意してください。