La haute disponibilité et l'équilibrage de charge sont essentiels pour construire des systèmes qui restent en ligne et gèrent le trafic efficacement, même en cas de défaillances ou de forte demande. La haute disponibilité assure la disponibilité en éliminant les points de défaillance unique et en utilisant la redondance, tandis que l'équilibrage de charge distribue le trafic pour éviter la surcharge des serveurs.
Points clés à retenir :
- Haute disponibilité : Maintient les systèmes en fonctionnement malgré les défaillances. Le temps de disponibilité est mesuré en « neuf » (par exemple, 99,99 % = ~52,6 minutes de temps d'arrêt/an).
- Équilibrage de charge : Dirige le trafic entre les serveurs pour maintenir les performances et éviter les goulots d'étranglement.
- Techniques de haute disponibilité :
- Redondance : Plusieurs serveurs ou composants prêts à prendre le relais en cas de défaillance.
- Vérifications de santé : Surveiller proactivement la santé des serveurs pour éviter les perturbations.
- Basculement : Commutation automatique vers les systèmes de secours en cas de problème.
- Algorithmes d'équilibrage de charge :
- Round Robin : Parcourt les serveurs de manière uniforme.
- Connexions minimales : Envoie le trafic au serveur le moins occupé.
- Hash IP : Achemine les demandes du même utilisateur vers le même serveur.
- Hash cohérent : Limite la redistribution du trafic lors de l'ajout/suppression de serveurs.
- Équilibrage de charge de couche 4 vs couche 7 :
- Couche 4 : Rapide, fonctionne au niveau de la couche transport (routage basé sur IP/port).
- Couche 7 : Plus intelligent, fonctionne au niveau de la couche application (routage basé sur les URL, les en-têtes, etc.).
En combinant ces stratégies, les systèmes peuvent évoluer efficacement, minimiser les temps d'arrêt et fournir un service fiable dans des conditions variables.
Qu'est-ce que la haute disponibilité dans la conception de systèmes ?
Définir la haute disponibilité
La haute disponibilité (HA) garantit que les systèmes restent opérationnels et accessibles même lorsque des parties du système défaillent. Il s'agit de fournir un service ininterrompu, peu importe les perturbations qui surviennent.
« La haute disponibilité (HA) est une caractéristique d'un système qui vise à assurer un niveau de performance opérationnelle convenu, généralement le temps de disponibilité, pour une période plus longue que la normale. » – Robert Sheldon, Contributeur technique, TechTarget [6]
La disponibilité est souvent exprimée en « neuf », qui représentent les pourcentages de disponibilité. Par exemple :
- 99,9 % (trois neuf) : Environ 8,77 heures de temps d'arrêt par an
- 99,99 % (quatre neuf) : Environ 52,6 minutes de temps d'arrêt par an
- 99,999 % (cinq neuf) : Seulement environ 5,26 minutes de temps d'arrêt par an
Ces chiffres ne sont pas seulement théoriques - ils ont des conséquences financières réelles. En 1996, un rapport IBM de 1998 estimait que les temps d'arrêt coûtaient aux entreprises américaines 4,54 milliards de dollars. Clairement, les enjeux de la disponibilité sont élevés.
Comment atteindre la haute disponibilité
Atteindre la haute disponibilité nécessite une planification minutieuse et des stratégies pour maintenir les systèmes résilients. Voici quelques méthodes clés :
-
Éliminer les points de défaillance unique (SPOF) : Un seul composant défaillant ne devrait pas arrêter l'ensemble du système. Par exemple, Stripe atteint 99,99 % de disponibilité pour son API de paiement en utilisant le sharding de base de données conscient des zones. Chaque fragment de données a un nœud primaire dans une zone de disponibilité et des répliques synchrones dans deux autres. Cette configuration permet un basculement inférieur à la seconde tout en maintenant une faible latence - critique pour leurs opérations [7].
-
Redondance : La duplication des composants critiques garantit que les sauvegardes sont prêtes à prendre le relais en cas de défaillance. Netflix a démontré cela lors de la panne AWS US-East-1 en décembre 2021. Leur architecture multi-région active-active a automatiquement redirigé le trafic vers les régions saines. Ils utilisent également des outils comme « Chaos Monkey » pour simuler des défaillances, garantissant que leurs processus de récupération fonctionnent comme prévu [7].
-
Vérifications de santé approfondies : Celles-ci vont au-delà des vérifications de base pour assurer la fonctionnalité complète. Par exemple, au lieu de simplement confirmer qu'une base de données est en cours d'exécution, une vérification de santé pourrait vérifier que la base de données peut exécuter des requêtes. Cette approche proactive permet les basculements automatisés avant que les utilisateurs ne soient affectés [7].
Ensuite, nous explorerons comment l'équilibrage de charge joue un rôle crucial dans le soutien de la haute disponibilité.
Comment l'équilibrage de charge soutient la haute disponibilité
Comment fonctionnent les équilibreurs de charge
L'équilibrage de charge joue un rôle critique pour assurer la haute disponibilité en dirigeant efficacement le trafic et en maintenant le temps de disponibilité du système. Pensez aux équilibreurs de charge comme des contrôleurs de trafic compétents, stratégiquement placés entre les utilisateurs et les serveurs pour guider chaque demande vers la meilleure destination possible.
« Un équilibreur de charge est fondamentalement un agent de circulation se tenant à l'intersection entre les clients et les serveurs, dirigeant chaque demande vers la destination la plus appropriée en fonction d'un ensemble de règles, de politiques et d'observations en temps réel sur la santé et la capacité du pool de serveurs. » – Matt Klein, Créateur d'Envoy Proxy [5]
Ces systèmes surveillent constamment la santé des serveurs backend. Si un serveur cesse de répondre, l'équilibreur de charge redirige rapidement le trafic vers les serveurs fonctionnels, garantissant un service ininterrompu.
Les équilibreurs de charge sont déployés à différents points de l'architecture d'un système : entre les utilisateurs et les serveurs web, entre les serveurs web et les serveurs d'application, et même entre les serveurs d'application et les bases de données [4]. Cette approche en couches assure un flux constant de trafic dans l'ensemble du système.
Pourquoi l'équilibrage de charge améliore la haute disponibilité
L'avantage remarquable de l'équilibrage de charge est sa capacité à prévenir les goulots d'étranglement et à éliminer les points de défaillance unique. En répartissant les demandes sur plusieurs serveurs, aucun serveur n'est surchargé, ce qui aide à maintenir un service continu [5].
L'équilibrage de charge soutient également l'évolutivité horizontale, ce qui facilite l'ajout de serveurs supplémentaires à mesure que le trafic augmente sans compromettre la stabilité du système. Par exemple, dans les années 2010, un serveur de 5 000 $ exécutant HAProxy open-source gérait les charges de trafic qui nécessitaient auparavant une solution matérielle de 100 000 $ [5].
Cette méthode facilite également la maintenance et les mises à niveau sans causer de temps d'arrêt. Elle permet des déploiements sans temps d'arrêt transparents, donnant aux équipes la flexibilité de faire des changements sans interrompre l'accès des utilisateurs [8].
Cependant, il est essentiel de s'assurer que l'équilibreur de charge lui-même ne devient pas un point faible. L'utilisation d'équilibreurs de charge redondants dans des configurations actif-passif ou actif-actif garantit que si l'un échoue, un autre prend le relais immédiatement [2].
Ensuite, nous plongerons dans les algorithmes qui rendent l'équilibrage de charge si efficace dans le cadre de votre préparation aux entretiens techniques et comment choisir le bon pour vos besoins.
Algorithmes d'équilibrage de charge expliqués
Algorithmes d'équilibrage de charge principaux
Choisir le bon algorithme est essentiel pour distribuer le trafic efficacement. Round Robin est une méthode simple qui parcourt les serveurs séquentiellement, envoyant des demandes à chacun à tour de rôle. C'est un excellent choix pour les configurations où les serveurs ont du matériel identique et exécutent des applications sans état. Fait intéressant, c'est l'algorithme par défaut pour NGINX et est utilisé dans plus de 100 000 déploiements[9][16].
Connexions minimales va plus loin en surveillant les sessions actives et en dirigeant les nouvelles demandes vers le serveur avec le moins de connexions actuelles. Cela le rend idéal pour les scénarios avec des connexions longue durée, comme WebSockets, les plateformes de streaming ou les bases de données où les durées de session varient considérablement. HAProxy s'appuie sur ceci comme valeur par défaut pour l'équilibrage de charge TCP[10][16].
Pour les applications nécessitant la persistance de session, telles que les paniers d'achat ou les systèmes de chat, IP Hash garantit que les demandes du même IP client sont toujours acheminées vers le même serveur. Cependant, cela peut créer une distribution inégale du trafic si de nombreux clients partagent une seule adresse IP, comme ceux derrière un NAT[12][14].
Hash cohérent est particulièrement utile lors de la mise à l'échelle, car il limite le nombre de demandes remappées à environ 1/n lorsqu'un serveur est ajouté ou supprimé. Cette fonctionnalité est particulièrement précieuse pour les caches distribués comme Redis ou Memcached, qui utilisent souvent des nœuds virtuels pour assurer une distribution équilibrée[11][12].
Les versions pondérées d'algorithmes comme Round Robin et Connexions minimales permettent au trafic d'être distribué en fonction de la capacité du serveur. Par exemple, un serveur avec un poids de 10 gérera deux fois le trafic d'un avec un poids de 5. Temps de réponse minimum combine la vitesse et la charge en dirigeant le trafic vers le serveur avec le temps de réponse le plus rapide et le moins de connexions, tandis que les méthodes basées sur les ressources allouent le trafic dynamiquement en fonction de l'utilisation réelle du CPU et de la mémoire[9][10][13].
Sélectionner le bon algorithme
Votre choix d'algorithme dépend de facteurs tels que les capacités des serveurs, les types de connexion et les exigences de session.
« Une bonne règle de base est de commencer simple et d'évoluer selon les besoins. » – Maurice McMullin, Principal Product Marketing Manager, Progress Kemp[9]
Si vos serveurs sont identiques et gèrent des demandes rapides et sans état, Round Robin est un point de départ fiable. Cependant, si votre pool de serveurs varie en capacité, les algorithmes pondérés peuvent aider à distribuer le trafic plus uniformément sans surcharger les machines plus faibles[9][10].
Pour les charges de travail mixtes, telles que les applications gérant à la fois des appels API brefs et de longs téléchargements, Connexions minimales est un bon choix. Les systèmes qui s'appuient fortement sur la mise en cache locale, en revanche, bénéficient du Hash cohérent, qui améliore les taux de succès du cache en maintenant un routage cohérent[11][16].
« Choisir le mauvais algorithme gaspille la capacité - les demandes s'accumulent sur les serveurs inactifs tandis que d'autres débordent. » – Sanjeev Sharma, Ingénieur Full Stack, E-mopro[11]
Les applications avec état, comme celles nécessitant l'adhérence de session, dépendent souvent du Hash IP ou de l'affinité basée sur les cookies, bien que ces méthodes puissent réduire l'efficacité de la distribution de charge[15]. Pour la flexibilité, HAProxy offre plus de 13 algorithmes différents pour s'adapter à diverses configurations d'infrastructure[13].
Enfin, les vérifications de santé robustes sont essentielles pour identifier et supprimer les serveurs défaillants du pool. Commencer par Round Robin pour les tests de connectivité de base est une approche pratique, mais l'évolution de votre stratégie en fonction des données de performance réelles donnera les meilleurs résultats[11][15].
Le guide ultime des équilibreurs de charge (Fondamentaux de la conception de systèmes)
Construire un équilibreur de charge hautement disponible
Plongeons dans les stratégies de création d'un équilibreur de charge résilient et hautement disponible, en nous appuyant sur les concepts de haute disponibilité et d'équilibrage de charge.
Conception d'équilibreur de charge multi-niveaux
S'appuyer sur un seul équilibreur de charge est un risque qu'aucun système à grande échelle ne peut se permettre. Pour résoudre ce problème, de nombreuses architectures implémentent une approche multi-niveaux. Au niveau supérieur, l'équilibrage de charge serveur global basé sur DNS (GSLB) dirige le trafic entre les régions géographiques. En dessous, les équilibreurs de charge régionaux de couche 4 (L4) et de couche 7 (L7) gèrent la distribution du trafic dans les centres de données individuels. Pendant ce temps, les mailles de services gèrent la communication entre les microservices en interne.
« Le choix entre L4 et L7 n'est pas l'un ou l'autre. Les architectures les plus résilientes les superposent, utilisant L4 pour la distribution brute et la tolérance aux pannes à la périphérie, et L7 pour le routage conscient de l'application plus proche des services. » - Matt Klein, Créateur d'Envoy Proxy [5]
Cette conception en couches garantit qu'aucun composant unique ne devient un goulot d'étranglement. Par exemple, AWS Elastic Load Balancing déploie automatiquement des nœuds redondants dans plusieurs zones de disponibilité pour renforcer la fiabilité. Pour rendre le basculement DNS efficace, définissez votre Time-to-Live (TTL) à 60 secondes ou moins avant les modifications d'infrastructure. Les valeurs TTL plus élevées peuvent faire que les clients continuent à accéder aux serveurs défaillants même après le basculement [17].
L'étape suivante ? Intégrer les vérifications de santé et les mécanismes de basculement pour maintenir cette résilience en couches.
Vérifications de santé et basculement
La surveillance de la santé est au cœur du maintien de votre équilibreur de charge en bon état de fonctionnement. Il y a deux méthodes principales :
- Vérifications actives : L'équilibreur de charge initie des sondes, telles que des poignées de main TCP ou des demandes HTTP, en s'attendant à une réponse 200 OK.
- Vérifications passives : Il observe le trafic en direct pour les signes d'avertissement tels que les erreurs 5xx ou les délais d'expiration.
Pour affiner ce processus, définissez des seuils qui marquent un serveur comme malsain après deux défaillances et nécessitent trois à cinq vérifications réussies avant de le remettre en ligne [18].
D'autres techniques comme le drainage de connexion et les mécanismes de démarrage lent améliorent encore la fiabilité. Le drainage de connexion garantit que les demandes actives se terminent avant la suppression d'un serveur, tandis que le démarrage lent augmente le trafic vers les instances nouvellement récupérées, évitant les pics soudains. Pour les applications avec état, synchronisez les tables de session entre les équilibreurs de charge actifs et de secours pour éviter les perturbations des utilisateurs lors des basculements [3].
Une fois les vérifications de santé en place, le prochain objectif est d'éliminer les points de défaillance unique de l'équilibreur de charge.
Prévention des défaillances d'équilibreur de charge
La redondance est la clé pour éviter la défaillance de l'équilibreur de charge. Deux configurations courantes sont les configurations Actif-Passif et Actif-Actif :
- Dans une configuration Actif-Passif, un équilibreur de charge gère le trafic tandis qu'une unité de secours le surveille à l'aide de signaux de battement cardiaque. Si le primaire échoue, le secours prend le relais de l'adresse IP virtuelle (VIP) partagée en utilisant VRRP (avec des outils comme keepalived).
- Une configuration Actif-Actif va plus loin, avec tous les équilibreurs de charge traitant le trafic simultanément. Cette configuration s'appuie sur le routage BGP et ECMP (Equal Cost Multi-Path) pour distribuer le trafic uniformément, en mettant à l'échelle la capacité à mesure que d'autres équilibreurs de charge sont ajoutés.
| Fonctionnalité | Actif-Passif | Actif-Actif |
|---|---|---|
| Gestion du trafic | Un équilibreur de charge gère le trafic | Tous les équilibreurs de charge gèrent le trafic |
| Complexité | Inférieure ; standard pour la plupart des configurations | Supérieure ; nécessite une mise en réseau avancée |
| Capacité | Limitée à la capacité d'une unité | Évolue avec le nombre d'unités actives |
| Vitesse de basculement | Quasi-instantanée via VRRP/battement cardiaque | Continu ; le trafic se déplace automatiquement |
Pour calculer le temps d'arrêt maximal du basculement, utilisez cette formule : Durée = TTL DNS + (Intervalle de vérification de santé × Seuil malsain) [17].
Par exemple, un proxy d'équilibreur de charge d'application régional gère généralement jusqu'à 600 nouvelles connexions HTTP ou 150 HTTPS par seconde [17]. Les tests réguliers d'injection de pannes garantissent que les unités de secours et les transitions VIP fonctionnent comme prévu, maintenant votre système préparé aux défaillances du monde réel.
Équilibrage de charge de couche 4 vs couche 7
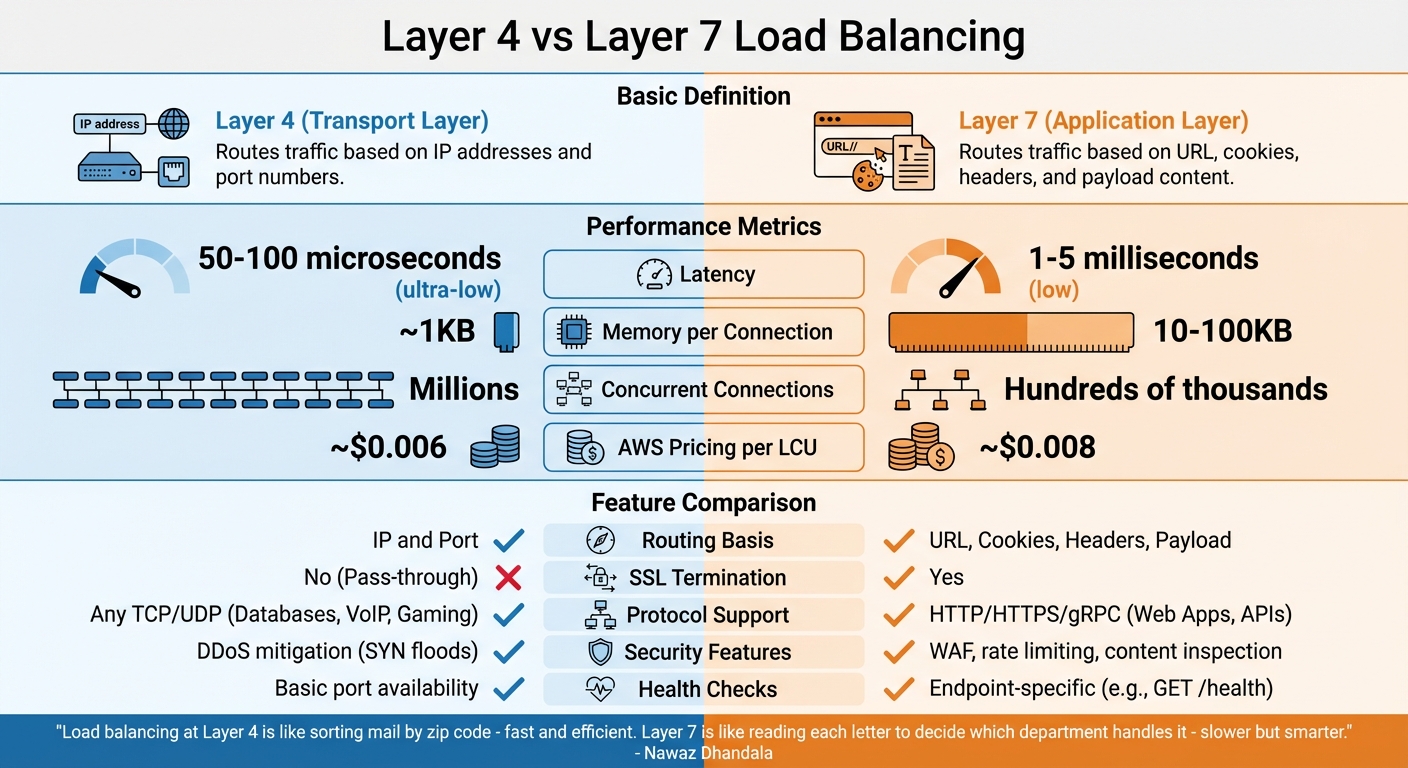
La distinction entre l'équilibrage de charge de couche 4 et de couche 7 réside dans la façon dont ils fonctionnent dans la pile réseau. Chacun offre un équilibre unique entre la vitesse et la fonctionnalité, selon vos besoins.
Couche 4 et couche 7 expliquées
Les équilibreurs de charge de couche 4 (couche transport) fonctionnent au niveau TCP/UDP, acheminant le trafic uniquement en fonction des adresses IP et des numéros de port. Ils n'inspectent ni ne déchiffrent le contenu des paquets, mais transfèrent plutôt le trafic à l'aide de méthodes telles que NAT (Network Address Translation) ou Direct Server Return (DSR). Cette simplicité permet une manipulation rapide des paquets sans maintenir l'état au niveau de l'application [19].
Les équilibreurs de charge de couche 7 (couche application), en revanche, fonctionnent au niveau HTTP/HTTPS. Ils terminent les connexions client, inspectent les données d'application, puis acheminent le trafic en fonction de facteurs tels que les en-têtes, les cookies, les URL ou les charges utiles de demande. Cette inspection plus approfondie permet une prise de décision plus avancée, mais nécessite d'établir des connexions séparées avec le client et le serveur backend [19].
« L'équilibrage de charge à la couche 4 est comme trier le courrier par code postal - rapide et efficace. La couche 7 est comme lire chaque lettre pour décider quel département la traite - plus lent mais plus intelligent. » - Nawaz Dhandala, Auteur, OneUptime [19]
En termes de performance, la couche 4 vante une latence ultra-faible, généralement autour de 50–100 microsecondes, et utilise une mémoire minimale. Pendant ce temps, la couche 7 introduit une latence légèrement plus élevée dans la plage de 1–5 millisecondes en raison de la mise en mémoire tampon et de l'analyse des demandes. La couche 4 peut gérer des millions de connexions simultanées, tandis que la couche 7 est généralement adaptée pour gérer des centaines de milliers de demandes par seconde [19].
Comparaison de la couche 4 et de la couche 7
Le bon choix entre la couche 4 et la couche 7 dépend de votre charge de travail et de vos objectifs. La couche 4 est idéale pour maximiser le débit, soutenir les protocoles non-HTTP (comme PostgreSQL ou Redis) ou maintenir le trafic chiffré sans déchiffrement à l'équilibreur de charge [19]. En revanche, la couche 7 est mieux adaptée aux applications web nécessitant des fonctionnalités telles que le routage basé sur le chemin (par exemple, /api vs /static), la terminaison SSL ou les outils de sécurité avancés tels que les pare-feu d'application web (WAF) [19].
| Fonctionnalité | Couche 4 (Transport) | Couche 7 (Application) |
|---|---|---|
| Base de routage | IP et port | URL, cookies, en-têtes, charge utile |
| Latence | Ultra-faible (50–100 µs) | Faible (1–5 ms) |
| Mémoire par connexion | ~1 KB | 10–100 KB |
| Terminaison SSL | Non (Pass-through) | Oui |
| Support de protocole | Tout TCP/UDP (par exemple, bases de données, VoIP, jeux) | HTTP/HTTPS/gRPC (par exemple, applications web, API) |
| Fonctionnalités de sécurité | Atténuation DDoS (par exemple, inondations SYN) | WAF, limitation de débit, inspection de contenu |
| Tarification AWS (par LCU) | ~0,006 $ | ~0,008 $ |
Quand il s'agit de vérifications de santé, la couche 4 s'appuie sur des tests de disponibilité de port de base, garantissant que le serveur est accessible. La couche 7, cependant, peut effectuer des vérifications plus détaillées en ciblant des points de terminaison spécifiques (par exemple, GET /health) pour vérifier que la logique d'application fonctionne comme prévu [19].
Conclusion
La haute disponibilité et l'équilibrage de charge ne sont pas seulement des considérations techniques - ils sont l'épine dorsale de la conception moderne des systèmes. Ces concepts sont essentiels pour maintenir la confiance des utilisateurs, générer des revenus et assurer la continuité opérationnelle. En supprimant les points de défaillance unique et en distribuant efficacement le trafic, ils maintiennent les systèmes en bon état de fonctionnement même en cas de pannes de serveur ou de pics de trafic inattendus.
L'évolution des solutions matérielles coûteuses aux solutions logicielles a rendu la fiabilité au niveau de l'entreprise plus accessible. Des services comme AWS ELB et Google Cloud Load Balancing offrent désormais des garanties de disponibilité impressionnantes (99,99 %), se traduisant par seulement 52 minutes de temps d'arrêt par an [1].
Les équilibreurs de charge agissent comme plus que des distributeurs de trafic - ce sont les cerveaux derrière les déploiements transparents, la protection DDoS, la terminaison SSL et la mise à l'échelle horizontale. Ils permettent aux systèmes de s'adapter à la demande, qu'il s'agisse d'une plateforme de commerce électronique gérant une ruée des fêtes ou d'un réseau social gérant du contenu viral.
Pour atteindre une véritable fiabilité, la redondance est essentielle. Incorporez des dispositifs de sécurité à chaque couche, concevez les systèmes pour être sans état en utilisant des outils comme Redis pour la gestion des sessions, et menez des vérifications de santé qui évaluent les performances de l'application, pas seulement la disponibilité du serveur. L'aperçu de Willy Tarreau souligne l'importance d'adapter votre approche :
« L'algorithme d'équilibrage de charge idéal n'existe pas en abstrait -- il existe par rapport à votre charge de travail » [5].
Que vous vous prépariez pour un entretien de conception de système ou que vous construisiez une infrastructure de production, maîtriser ces principes est un changement de jeu. La haute disponibilité et l'équilibrage de charge travaillent main dans la main pour créer des systèmes qui évoluent efficacement et se rétablissent gracieusement - car même quelques minutes de temps d'arrêt peuvent avoir un impact sérieux sur votre résultat net [3].
FAQ
Comment choisir le bon objectif de disponibilité (99,9 vs 99,99 vs 99,999) pour mon système ?
Lors de la définition d'un objectif de disponibilité, considérez la criticité de votre système. Pour les systèmes moins critiques, une disponibilité de 99,9 % (environ 8,76 heures de temps d'arrêt par an) est généralement suffisante. Cependant, pour les services critiques - comme ceux dans le secteur de la santé ou de la finance - vous voudrez un objectif plus élevé, tel que 99,99 % (environ 52,6 minutes de temps d'arrêt par an) ou même 99,999 % (seulement 5,26 minutes par an). Gardez à l'esprit que l'atteinte de niveaux de disponibilité plus élevés exige un investissement beaucoup plus important, il est donc essentiel de peser vos besoins de fiabilité par rapport aux coûts associés.
Qu'est-ce qu'une vérification de santé « approfondie » devrait inclure au-delà d'un simple ping ?
Lors de l'exécution d'une vérification de santé, il est important d'aller au-delà d'un simple ping. Une vérification de santé approfondie devrait évaluer toutes les dépendances critiques, comme les bases de données et les files d'attente de messages. Cette approche fournit une image plus claire de la santé globale du système et aide à minimiser le risque de défaillances en cascade.
Quand dois-je utiliser l'équilibrage de charge de couche 4 vs couche 7 en production ?
Pour l'équilibrage de charge de couche 4, les décisions de routage sont prises en fonction des adresses IP et des ports. Cette approche est parfaite pour les applications haute performance car elle minimise les frais généraux et offre un routage rapide basé sur le protocole.
D'autre part, l'équilibrage de charge de couche 7 se concentre sur le routage conscient de l'application. Il utilise du contenu comme les URL, les en-têtes ou les cookies pour prendre des décisions, ce qui le rend idéal pour des scénarios plus complexes. Cependant, soyez conscient que cette méthode implique une latence plus élevée et utilise plus de ressources par rapport à la couche 4.